
Two VIFs, One Hybrid Strategy
Two VIFs, One Hybrid Strategy
Cloud Hybrid Networking often forces you to choose between two useful things that don’t like sharing: fine-grained, centrally managed app connectivity and cheap, high-throughput bulk transfers.
So is there a compromise to solve this dilemma? Well yes there is, the compromise is to run two Direct Connect (DX) Virtual Interfaces (VIFs) in parallel. You would have a Transit VIF into a Transit Gateway (TGW) for your Application Traffic, and a Private VIF into a Virtual Private Gateway (VGW) or a VGW via a Direct Connect Gateway (DXGW) as a dedicated, bulk lane for bulk migration or replication.
This overcomes the costly extra of your Transit Gateway processing huge loads of data be that migration data or ongoing replication. This solution can be as short term or as long term as you need it to be dependent on your use case.
The following diagram is a simple architecture diagram of what we would aim to achieve.
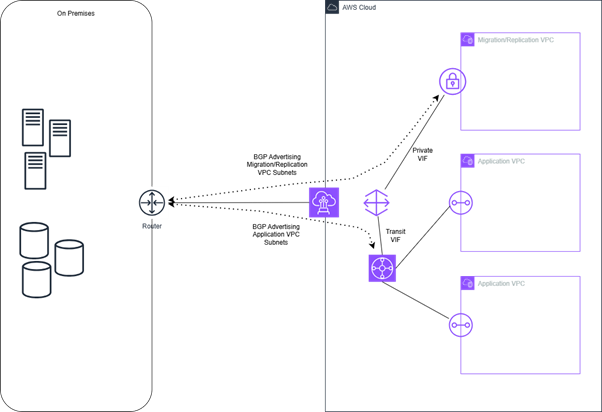
Core Design Principle – Route by purpose not convenience
What does this design principle mean?
In my mind it means don’t let convenience create accidental costs, asymmetric routing or be the easy default, Design intentionally and stand by decisions whilst they make commercial sense to do so.
What does this mean in a practical sense?
- Identify and put migration targets into dedicated subnets and advertise them as more specific prefixes over the Private VIF
- Advertise Broader enterprise aggregate subnets over the Transit VIF
- Let Border Gateway Protocol (BGP) Longest-Prefix match do the heavy lifting
Concrete Examples
If we take this first example, we have a single DX Connection between Amazon Web Services (AWS) and the On Premise environment. A migration/replication Virtual Private Cloud (VPC) with the subnet 10.0.0.0/24, and two application VPC’s with subnets 10.0.32.0/24 and 10.0.33.0/24. The migration/replication subnet Private VIF will advertise the specific subnet 10.0.0.0/24. The Transit VIF will advertise an aggregate subnet for the whole AWS environment 10.0.0.0/16.
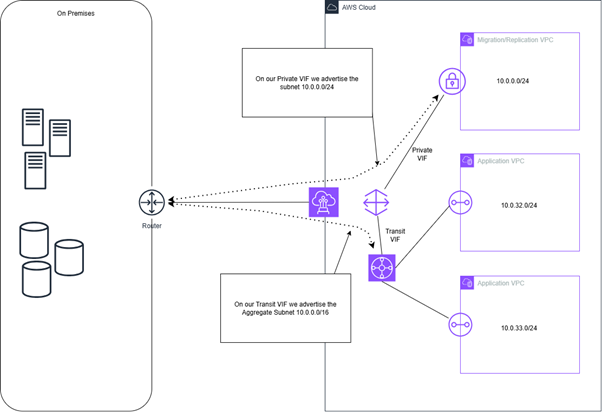
In this simple example routing decisions are really simple, when traffic is arriving from on prem to either the migration/replication VPC or either of the application VPCs, the Longest Prefix match rule is engaged and traffic is routed appropriately based on its destination address.
Ok I appreciate that this is a simple example so lets look at something a little more complex and see what other BGP knobs we can turn to influence paths and resilience.
So below is a more complex setup with dual Direct Connect connections multiple VIFs and a plethora of options open to us.
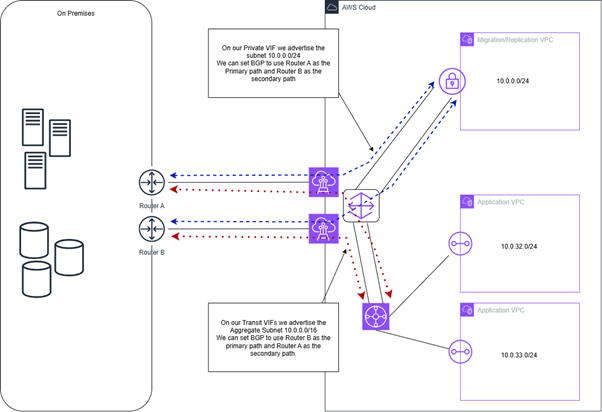
So in this example there is a bit more going on we have the dual direct connects and now we have dual VIFs for each type (four BGP paths in total). So in this scenario what can we do? One of the first things on my mind to start with is making sure we get the most our of our two links, coming from a networking background we want to make sure both paths are well utilised. Now I could leave this up to BGP to Equal Cost Multi Path (ECMP) across the available links by configuring them all the same, but remember our core design principle Route by Purpose. So we want to make sure we are in full control of which paths traffic takes.
With that in mind this means we can split the traffic over two paths and still maintain resiliency. For the migration/replication traffic we would make the path via Router A our primary path with the ability to failover to the other path in the event of a problem. With our application traffic we would reverse this so Router B would be our primary path and would failover to the other path in the event of issues.
There are a few ways we can this:
- The first way is probably the easiest and doesn’t really need any additional configuration on the on prem side, to get BGP to make an informed decision on path we can use AS PATH Prepend, this means on our secondary path we would just prepend our Autonomous System Number (ASN) with our own ASN number again, this signals to BGP that the secondary route is a less optimal path and would there for not be selected as primary and would sit in the BGP candidate routing table until it was needed.
- The second way involves more configuration on the on prem side devices, as part of the route advertisements from On Prem we can use AWS pre-determined BGP Community Tags, when AWS receives these community tags it interprets if the connection is High, Medium or Low preference (this essentially BGP Local-Pref for those in the know). In this scenario prefixes with the highest preference are chosen over lower preferences.
This is pretty useful in terms of real world scenarios, although I would caution that if you want to fully utilise both links you ensure that during failover scenarios you ensure that your connections are sized appropriately to take all traffic, there are ways around this like configuring rate limits on your on prem devices etc to stop certain types of traffic swamping the links but this is going a bit beyond what this blog is about.
Cost Benefit Analysis
It goes without saying that this type of setup really needs to have a thorough cost benefit analysis carried out to ensure that is makes sense to implement.
In this scenario we are trying to trade the Transit Gateway Processing cost of data for simpler Direct Connect transfer fees for high amounts of bulk/replication data.
I would expect to be looking to use this type of setup in migration situations where huge amounts of data are being transferred to the AWS Cloud. I would be less likely to recommend this for replication unless it was significant to warrant this setup.
What should be considered with this setup?
Lets discuss some considerations when opting for this type of setup in AWS:
- Prefix structure – when you are thinking about IP subnet design, ensuring you have got no constraints early in the process making traffic steering harder, will make things easier in the long run
- Unintended propagation – for anyone that has worked in the networking arena will know this is a massive concern when using dynamic routing, so it stands to reason that we need to ensure that we are not propagating routes to incorrect places create alternative paths we are not aware of, so ensure that you validate paths after each change.
- Shifting security posture – if you have spent a lot of time ensuring that your traffic is inspected by either AWS firewall or a third party and then a new path is introduced that potentially will bypass this, analysing if you need to update how traffic is inspected is something to consider.
- Potential Observability gaps – with the introduction of additional AWS items such as Private VIFs and VGWs its essentially to ensure that the relevant monitoring and logging is setup to capture when you may have issues.
- Asymmetric Routing – If in some cases where you might have a Transit Gateway Attachment attached to migration/replication VPCs there is a higher chance of creating Asymmetric routing which is not desirable when you have pre-determined paths, so always ensure that you understand your routing path and regularly check after changes that the correct paths are still available and in use.
- Human Error – human intervention during changes is a big culprit for mis configuration, to avoid this ensure that you are using Infrastructure as Code as much as possible to lower this risk.
Final Thoughts
A Transit VIF and a Private VIF together let you have both centralized, scalable app networking and cheap, high-throughput data lanes, provided you design your prefixes, BGP policies, and TGW propagation with intent. The pattern is simple and the art is in the routing discipline and operational validation.



