
Logical Data Modelling: Identifying Entities
Logical Data Modelling: Identifying Entities
As we develop our Data Models, we must provide the ability to uniquely identify individual occurrences of each Entity.
This can provide the basis for Quality framework definitions (i.e. if a set of Attributes are needed to uniquely identify an Entity, then this information must be recorded), smooth the process of Data Migrations, and defend against duplicates. It is also needed to be able to refer to specific Entity instances.
Companies often shy away from this challenge by systematically adding a Numeric Identifier Attribute to every Entity, but this doesn’t truly address the issue. For instance, if the same Entity is apparent in two disparate systems, how is the Entity given the same identifier?
This latest blog in the series describes the problem in detail and provides the tools to help uniquely identify each instance of our Entities, solely using their Attributes. In a later blog, we will show how Relationships are sometimes needed to do this.
Unique Identifier Attributes
When carrying out operational activities, how can we ensure we are referring to the correct one?
For example, when talking to a Customer who has enquired about a Product on their last Order from one of the Club’s Shops, how do we know the identity of the product, order and shop to be able to effectively respond to the enquiry?
Defining Unique Identifier Attributes
If an Attribute is to form part of the Unique Identifier, it must:
- Be Mandatory
- Adhere to all the normal rules for Attributes covered in a previous blog: Logical Data Modelling: Entity Attributes
- Be Stable i.e. its value must not change over time
In Barker notation, any Unique Identifier should be prefixed with #.
Selecting Valid Unique Identifier Attributes
To help explain why adding a Numeric Attribute to an Entity to be used as the Unique Identifier is not always the best solution, look at the following example rows for a Player Entity:

Is the second record a duplicate? If using the Player Identifier as the unique identifier, then this would not be seen as a duplicate, when in reality it is.
Instead, it is real world uniqueness that should drive the discussion for Unique Identifiers.
Natural Keys
The first choice for Unique Identifiers should be Natural Keys.
These are based upon one or more real world attributes of the Entity and are intrinsically part of the definition of the Entity in the real world.
For example, a ‘Client Reference’ is not a Natural Key. External organisations or people are very unlikely to have a magic number that can universally identify them.
In the absence of being able to otherwise recognise that it is the same organisation, it is highly likely that the same entity will be allocated two different client references over time.
Unfortunately, Natural Keys are rare in the real world and this is particularly true for people and organisations – which are often at the heart of a business’ Data Model.
Creating a Natural Key Unique Identifier
Optimistically, let’s try to find a Natural Key to use as a Unique Identifier for a Player Entity.
In reality, we identify people via their names. Our first-cut of the Unique Identifier for a Player Entity:

It doesn’t take long before we encounter people with the same names.
Could we add another attribute such as Date Of Birth to enforce uniqueness? Maybe, but we will eventually hit the same problem.
You might hit this problem earlier than you think, as people tend to name their children with names that are popular at that time. Not limited to this example, human nature will introduce more duplicates than a random selection would create.
Another problem is that humans are ever increasingly less willing to divulge personally identifiable information, that could otherwise form the basis of our Unique Identifiers.
Taking a look instead at our Organisation Entity, the Name may not be a good Unique Identifier because an organisation’s name may change, or use a trading name.
So what should we do in these cases?
Externally mastered Unique Identifiers
In the absence of a Natural Key, an external referencing system that can be used to master the Unique Identifier will be the next best approach.
For example:
- Tax Number
- An ISO Code
- Standard Industry Code
If adopting this technique, consider the following:
- Could the mastering authority reallocate codes?
- Will the mastering authority change?
- Does the mastering authority cover all instances of the Entity?
If all the above are ‘Yes’, then you can look to use it in your model.
If the organisations we are interested in are all Companies, then it could be appropriate to model it accordingly:

So, we could use Companies House as the external mastering authority to uniquely identify all UK based football clubs and organisations.
Here is some sample data to illustrate:

External Unique Identifier Domains
When using this approach, you may notice that we are limited to recording only organisations that are registered UK companies.
If we want to support, for example, a foreign Football Club, a Registered Charity or an Education Institution, we will need to extend this to provide the ability to record the body that masters the Registration Numbers.
By adding the Registration Body Name to create a Compound Unique Identifier, our new look Entity is as follows:
Demonstrated with some sample data:
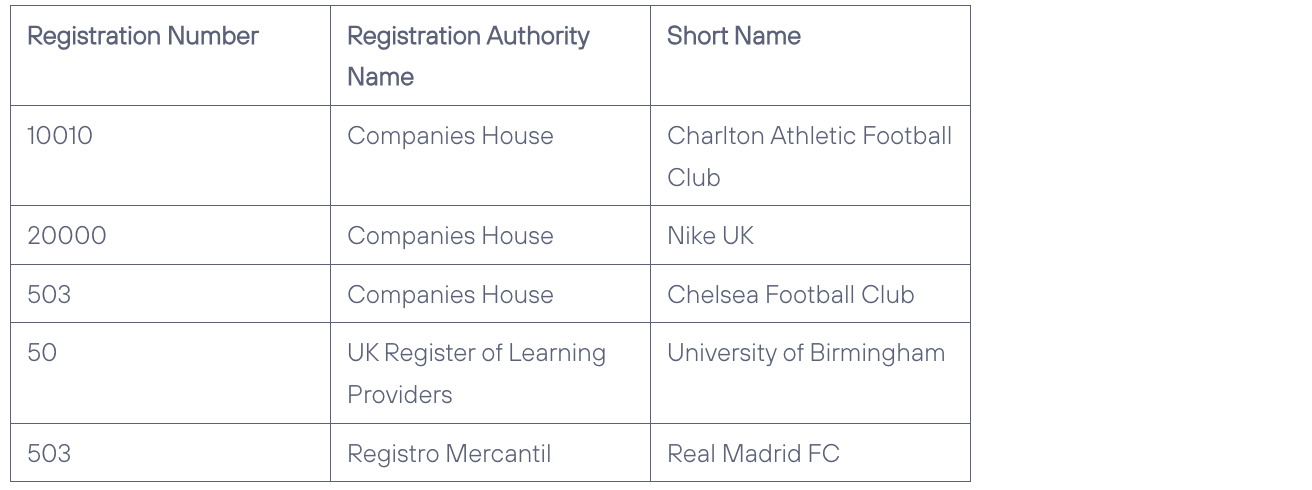
The ability to record the external mastering body needs to be built into your models whenever the Unique Identifier is externally mastered.
Even if not currently required, it will help future proof the models. For example, Charlton may not currently be interested in recording the details of football clubs from abroad, but we will in the future when competing in international club competitions.
Internally mastered Unique Identifiers
In the absence of a Natural Key or External Mastering Key exists, you may be able to use a Master Data Management approach.
This relies on the organisation performing due diligence processes and then allocating a Master Data Key to each instance.
So for example, all Client Reference Identifiers are ratified as part of your Master Data Management.
This isn’t ideal and not very scalable but may be the best that can be achieved for some Entities.
Alternate Keys and Descriptors
In some instances, with good reason, we may have dismissed some first-cut candidate keys from forming the Unique Identifier.
These can form good candidates for ‘Alternate Keys’ in your models, and can play important roles in identifying Entity instances within your organisation.
When these attributes allow easy recognition of each instance of an Entity they can be referred to as ‘Descriptors’. It is highly likely someone at the other end of the line would know their club’s name, but not the registration number with Companies House.
Surrogate Keys
Surrogate Keys typically use a Number type Attribute to define the Unique Identifier.
I suggested the systematic addition of these to every single Entity masks the problem of being able to properly identify each occurrence, and shouldn’t be used as a universal solution.
However, there is a place for these in Logical Data Models: when the organisation has total control over the identification and definition for each instance of the Entity. We explore this idea next.
Internally Mastered Reference Data
For instance, we may have a Referee Preference Level Entity to have some ratified values in it:

We can define and maintain this wholly within the organisation. Since we can control the unique identity of each Entity instance, there is no problem in allocating a Surrogate Key for it.
However, using an internally generated number for a person as a Surrogate Key is not a valid candidate for a Unique Identifier because people exist in the absence of our organisation, and created beyond the control of our organisation. A caller cannot ask whether they are ‘Person 1’, hence its use as a Surrogate Key should be avoided.
Internally Mastered Transactional Data
Similarly, because we create Transactional data within the operations of our organisation, it is perfectly valid to allocate Surrogate Keys for these kind of Entities.
For instance, we can allocate an Order Number as a Unique Identifier to each of the sales in our Club Shop.
This is an acceptable approach for a wide range of Transaction Entities. However, when discussing these occurrences with external bodies, it is unlikely they will be able to quote our internal references. Hence, we still need to think carefully how we would be able to identify each occurrence – for instance a payment, from their perspective.
Part of this identification might be to recognise the payment was related to that Client through a Relationship. This idea will be explored in a future blog.
