Introduction
Since the beginning of the digital age, there has been an exponential growth in the amounts of data being created. A 2013 study found that 90 percent of the world’s data was generated in the preceding two years alone. Furthermore, according to Forbes, there are 2.5 quintillion bytes of new data produced every day.
The internet, social media and the plethora of digital devices are responsible for the surge, as vast quantities of information are now collected in various structured and unstructured formats, including transactions, text, image, audio and video.
In practice, this all means that:
- the volume and speed at which data is being created is overwhelming;
- the traditional methods of how data is stored and analysed are increasingly becoming obsolete.
In terms of a solution, on the one hand, the adoption of cloud-based infrastructure, distributed storage systems, non-relational databases and big data processing technologies have provided an answer for data storage and processing. On the other, the development of machine learning, data science and AI (artificial intelligence) are providing new ways to analyse data at a larger scale.
The emergence of these fields, however, has been accompanied by a significant amount of hype and marketing buzzwords that are unhelpful and cause confusion. For that reason, it is necessary to clarify what is meant by data science and why it can provide value.
Fundamentals
One of the primary ways we understand the world is through data. Data is a capture of information about an entity or event that has occurred. The combining of this information can lead to knowledge about what has happened, which can then be applied into actions. This process is illustrated in the data pyramid below.
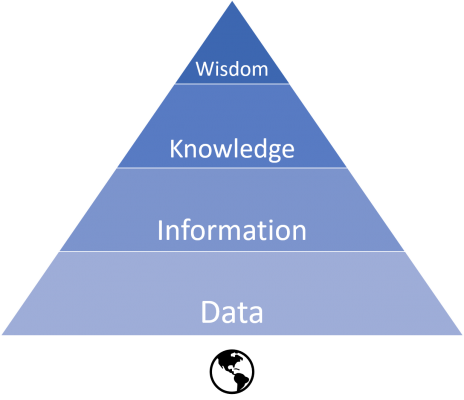
Data science is involved in the process of moving up the hierarchy from raw data to insights and wisdom. More specifically, data engineering is involved with the lower levels of the hierarchy and data science in the higher.
The advantage of using data is that it provides a fast and accessible means to gain an understanding of something. For example, by comparing the population size of two countries, you can quickly understand which is the bigger country.
As the saying goes ‘knowledge is power’, therefore, there is a massive demand to examine data effectively and place organisations in a more informed and competitive position. In the modern world, almost every aspect of a business is collecting data and doing something with it, including operations, marketing, HR, sales, customer service, IT and accounts. Equally, the use of data is not limited to one or two industries. It includes, tech, finance, retail, healthcare, education, sports, government, manufacturing, and almost every other industry imaginable.
Data science can help each of these domains obtain significant utility from data, allowing them to operate more efficiently. It can help identify unexpected patterns and trends in data, uncover insights about the business and predict what will happen with a strong degree of accuracy. At its core, though, data science is ultimately about improving decision-making.
Business Intelligence vs. Analytics vs. Data Science
At this point, you may be wondering what the difference is between business intelligence, analytics and data science; after all, each uses data to improve decision making. The best way to separate them, however, is by drawing a distinction between a reactive and proactive decision.
Generally speaking, the former involves looking at past data, analysing it and making a decision in response to it. Business intelligence falls clearly into this category, as it involves simply reporting what has previously happened. The latter, on the other hand, involves looking to the future and predicting what will happen, which is where data science belongs.
Data science is more complex than business intelligence, requiring a broad and unique skillset. Historically, data science emerged by combining industry knowledge with computer science and mathematics, as the Venn diagram below demonstrates. A data scientist tends to be skilled at both programming (R/Python/Scala) and statistics, which they utilise to extract meaning from large datasets and communicate the results.
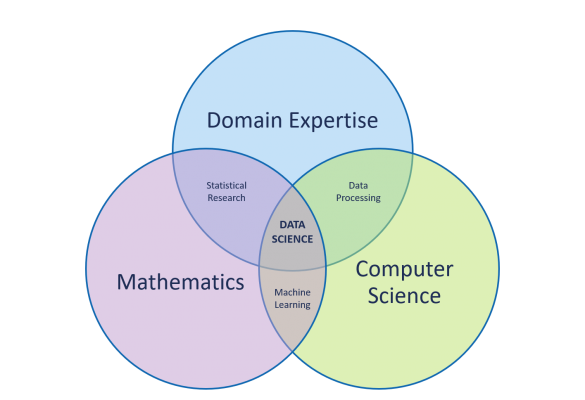
Analytics is a wider term that can fit into both categories. However, analytics can be broken into two subsets that make the classification more obvious: descriptive analytics, which describes what has happened in the past (reactive); and predictive analytics, which infers the future (proactive).
Prerequisites
For a data science project to maximise its success, there are certain requirements that need to be in place before the project commences.
Firstly, any data quality issues, such as missing data, duplicates or inaccuracies, need to be ironed out. Although some algorithms, like neural networks, are more robust to these issues than others, the rule ‘garbage in, garbage out’ still holds true. The output of a model is only as good as the input.
Second, it is difficult to produce a successful model if the data is stored and managed poorly. As Kelleher and Tierney (2018, pp. 73) note, having a data warehouse in place significantly reduces the time and effort associated with a data science project. It also helps to have a strong understanding of what has happened in the business, which can then be acquired through frequently reporting data.
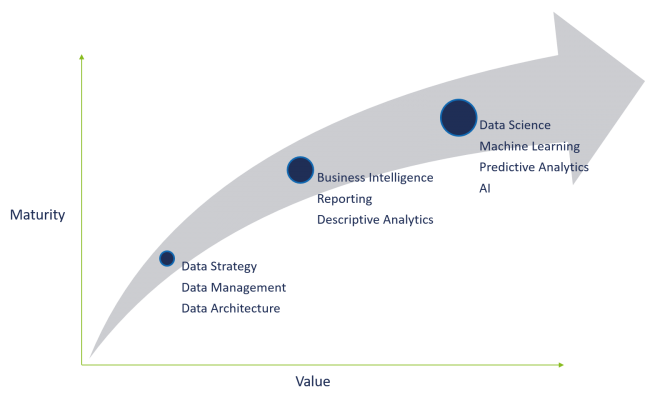
The chart above demonstrates the data maturity curve. As an organisation advances in data maturity, they then obtain more value from their data and can begin doing effective data science.
Real-world examples
In practice, data science has been used to solve various business problems. A typical example is the prediction of whether an employee will leave a company, known as churn, attrition or turnover. According to research by Oxford Economics, the average cost of replacing an employee is more than £30,000. For that reason amongst others, it is vital that a company can keep hold of its key employees and identify those at risk of leaving.
If the necessary prerequisites are in place, data scientists can help this situation by identifying the statistically significant features/variables that influence leaving a job, such as age, years at the company, distance to work etc. and then by training a model that predicts the probability that an employee will leave. As a result, a manager can see those employees at greater risk of leaving and put measures in place to alleviate it, i.e. giving a promotion, additional training or pay rise. This is an example of a classification problem, meaning that we are predicting a class or category (either leave or not leave).
The prediction of a continuous value is known as a regression problem. For example, if we are predicting future sales of a product by taking into account meaningful product features, such as price, reviews, marketing campaign type etc. the outcome would be a numeric, quantitative value that indicates the expected amount of sales. Other examples of regression include the prediction of salary, profit/loss and number of customers. These types of problems could also be predicted over time, known as time-series analysis or forecasting.
A further example of the application of data science is customer segmentation. A company with large numbers of customers can group them into distinct, manageable clusters based on their similarities and differences. For instance, if we are clustering customers based on interaction with emails and products purchased; we may label those that frequently open emails and have a high number of purchases as “loyal customers”, while those with little engagement and few purchases may be labelled as “dormant”. The customers with high email engagement but few purchases may be labelled as the “priority” for targeting, to turn engagement into purchases.
Summary
To conclude, the emergence of data science is a consequence of the amalgamation of mathematics and computer science to analyse data on a larger scale. Data science is in demand because it can improve decision making and allow businesses to be more proactive in their actions. Data science facilitates deeper understanding of data by identifying hidden/unexpected patterns, trends and insights within datasets, allowing for predictions to be made of what will happen in the future.