The aim of this blog is to explain how to create custom Purview processes, enabling you to add lineage from processes that are not tracked out of the box.
As covered in this blog, Azure Purview can help with understanding the lineage of your data, offering visibility of how and where data is moving within your data estate.
Lineage can only be tracked out of the box when using tools such as Data Factory, Power BI, and Azure Data Share. Lineage is lost when using other tools like Azure Functions, Databricks notebooks, or SQL stored procedures.
Using and authenticating with Purview
We will use PyApacheAtlas library to work with the Azure Purview APIs.
The first step is to connect to your Azure Purview account using Python (3.6+):
From the Azure portal, create a service principal and generate a secret (make a note of these).
Then, from within the Purview governance portal, select the root collection in the collections menu and select Role assignments. Assign the following roles to the service principal:
- Data Curator
- Data Source Administrator
- Collection Admin
See the Microsoft documentation for a detailed explanation of the above steps.
Now, authenticate to your Purview Account using oauth:
def authenticatePurview(account_name, tenantId, clientId, clientSecret):
oauth = ServicePrincipalAuthentication(
tenant_id=tenantId,
client_id=clientId,
client_secret=clientSecret
)
client = PurviewClient(
account_name = account_name,
authentication=oauth
)
return client
purviewAccount = "az-aoc-prv"
client = authenticatePurview(purviewAccount,TENANT_ID, CLIENT_ID, CLIENT_SECRET)
By passing the Azure Purview resource name, Azure tenant ID and client ID, and secret of the service principal, we create a PurviewClient object to interact with the Purview APIs.
Worked Example
We will follow the example of a simple ETL process.
Firstly, create a pandas dataframe like below. To benefit most from this blog and the Purview APIs in general, you should have a meta-data driven ETL process as this will make it easy to create the dataframe. Otherwise, you will first have to spend more time to create this.
Crucially, the source and target locations of your entities at each stage of the ETL within your different data stores must be known. For my example, these locations are split into a location and pattern. These will be used to create the Purview qualified names.

Pandas dataframe with entity locations
A copy of the ‘payroll.csv’ from ‘sourcesystem1’ starts in the RAW/sourcesystem1 directory in our datalake and a ‘employee.csv’ file is in RAW/sourcesystem2.
The first type of process is a Databricks notebook, it does some light cleansing and schema validation of each file and copies each to the BASE location as a parquet file. The ‘Dependency’ will be given to the name of that instance of the process. So here, there are two instances of the Databricks notebook process, each with a different name.
Then, a SQL stored procedure imports the files from the datalake into two tables in our data warehouse, in the BASE schema.
Finally, another SQL stored procedure transforms these two tables into an employee dimension in the WAREHOUSE schema.
For rows 0-4 a 1-1 mapping exists between the source and target so one process name (dependency) for each. However, for the ‘BASE WAREHOUSE TO DIM Employee’ dependency there are two rows because there is a many-to-one relationship.
Each ‘Dependency’ represents each piece of lineage in the ETL process.
Upload custom process
The next step is to create a new custom process by creating and uploading a EntityTypeDef object.
To define the relationship attributes we use AtlasRelationshipAttributeDef.
def create_process_entity_json(processName):
table_process_entity = EntityTypeDef(
name=processName,
superTypes=["Process"], # subtype of Process
relationshipAttributeDefs=[
{
"name": "outputs",
"typeName": "array<DataSet>", # process can take an array of datasets as inputs
"isOptional": True,
"cardinality": "SET",
"valuesMinCount": 0,
"valuesMaxCount": 2147483647, #max number of outputs
"isUnique": False,
"isIndexable": False,
"includeInNotification": False,
"relationshipTypeName": "process_dataset_outputs",
"isLegacyAttribute": True
},
{
"name": "inputs",
"typeName": "array<DataSet>",
"isOptional": True,
"cardinality": "SET",
"valuesMinCount": 0,
"valuesMaxCount": 2147483647, #max number of inputs
"isUnique": False,
"isIndexable": False,
"includeInNotification": False,
"relationshipTypeName": "dataset_process_inputs", # not a typo!
"isLegacyAttribute": True
}
]
)
return table_process_entity.to_json()
def upload_json_process(client, json_entity, force_update ):
upload_results = client.upload_typedefs(json_entity, force_update) #updates the process if exists
return upload_results
json_entity = create_process_entity_json("Dummy process")
upload_results = upload_json_process(client, json_entity, True)
We run the above 3 times, passing in ‘Databricks notebook validate schema’, ‘SQL Import Stored Procedure’ and ‘SQL Warehouse Transformation’, as we have three separate types of process.
You will not yet see anything change on the Purview UI. It is only once you create an instance of the process that they will appear amongst your other data sources.
Get entity type
Next, we must find the type of the entities we are tracking the lineage of. You will have to do this once for each different source type you have e.g. datalake file, azure sql table, azure sql view.
Locate an asset of the given entity type in Purview and find its guid:
![]()
Pass in the guid to the below function to get the Purview type:
def getEntityTypeOfGuid(guid): entity = client.get_entity(guid = guid) return entity['entities'][0]['typeName']
Now, you can pass in this type and the ‘qualified name’ which can be seen from the Purview UI to retrieve an entity from Purview, rather than its guid.
Example process
We will upload the ‘RAW TO BASE DATALAKE Payroll’ process as an example:
We hardcode these values for simplicity. However, when doing this for a client, I created a dictionary with entity stage as the key and added values for the associated Purview process, source, and target types. In this way, we can dynamically retrieve the items depending on the type of process.
sourceEntityType = 'azure_datalake_gen2_resource_set' #previously found this targetEntityType = 'azure_datalake_gen2_resource_set' purviewProcessName = 'Databricks notebook validate schema' #already created a process with this name
Filter dataframe to one dependency
Similarly, we hardcode to filter for one dependency whereas in practice we can iterate through every dependency. In this case, one row is returned since there is a 1:1 mapping between the files in RAW and BASE:
dep = 'RAW TO BASE DATALAKE Payroll' # hard code for one dependency dfFiltered = df[df[Dependency] == dep] # filter dataframe to one dependency
Create list of entities
This simply returns each row of the pandas dataframe as a dictionary and adds it to a list. Here, this will be one item.
def createEntityList(datawarehouseQueryPandasDF):
entitieslist = []
for index, row in datawarehouseQueryPandasDF.iterrows():
entitieslist.append(row.to_dict())
return entitieslist
entitieslist = createEntityList(dfFiltered) # create entity list
Create sources and target qualified name
These following functions define the rules to map the location/patterns in your dataframe to the qualified names in Purview.
Given the folder structure of my datalake, Purview knows that it is partitioned daily and creates only one asset for each entity rather than a different asset for each day, month or year.
The functions only return a list for the sources. This is because there can be multiple sources per process, but we only ever have one target.
# can be multiple sources for one target so returns a list
def createSources(entitieslist):
sources = []
for entity in entitieslist:
if (entity.get("SourceEntityStage") in ["RAW", "BASE"]):
sources.append(DatalakeRoot + str(entity.get("SourceLocation")) + "/{Year}/{Month}/{Day}/" + str(entity.get("SourcePattern")))
if (entity.get("SourceEntityStage") in ["BASE WAREHOUSE", "WAREHOUSE"]):
sources.append(AzureSqlRoot + str(entity.get("SourceLocation")) + "/" + str(entity.get("SourcePattern")) )
return sources
# can be multiple sources for one target, hence take first item in array since same target for one dependency code
def createTarget(entitieslist):
if (entitieslist[0].get("TargetEntityStage") in ["RAW", "BASE"]):
target = DatalakeRoot + str(entitieslist[0].get("TargetLocation")) + "/{Year}/{Month}/{Day}/" + str(entitieslist[0].get("TargetPattern"))
if (entitieslist[0].get("TargetEntityStage") in ["BASE WAREHOUSE", "WAREHOUSE"]):
target = AzureSqlRoot + str(entitieslist[0].get("TargetLocation")) + "/" + str(entitieslist[0].get("TargetPattern"))
return target
sources = createSources(entitieslist)
target = createTarget(entitieslist)
Get the entity metadata from Purview
This step retrieves the sources/targets from Purview. It should return the metadata of the Purview asset, if not then the entity type or qualified name is incorrect.
def getEntity(client, entityName, entityType):
targetEntities = client.get_entity(
qualifiedName=entityName,
typeName=entityType
)
return targetEntities
sourceEntities = getEntity(client, sources, sourceEntityType)
targetEntities = getEntity(client, target, targetEntityType)
Create the process inputs & outputs as json
For our processes, the outputs are a list of length one whereas the inputs can be a list of multiple json items.
def createProcessInputs(sourceEntities):
inputs = []
for sourceEntity in sourceEntities.values():
if len(sourceEntity) > 0:
for sourceEntityListItem in sourceEntity:
if type(sourceEntityListItem) is dict:
inputs.append(AtlasEntity( #input entity
name = sourceEntityListItem["attributes"]["name"],
typeName = sourceEntityListItem["typeName"],
qualified_name = sourceEntityListItem["attributes"]["qualifiedName"],
guid = sourceEntityListItem["guid"]
))
inputs_json = []
for input_entity in inputs:
inputs_json.append(input_entity.to_json(minimum=True)) ## add the atlas entity
return inputs_json
inputs_json = createProcessInputs(sourceEntities) # list of json inputs for the process
outputs_json = createProcessInputs(targetEntities) # list of json output for the process (length 1)
Create the process and upload to Purview
# create the AtlasProcess object
def createProcess(inputs_json, outputs_json, processType, dep, description):
process = AtlasProcess(
name=dep,
typeName= processType,
qualified_name=dep,
inputs=inputs_json,
outputs=outputs_json,
guid=-1,
attributes = {'description' : description}
)
return process
process = createProcess(inputs_json, outputs_json,purviewProcessName, dep, 'dummy description')
results = client.upload_entities(batch=[process]) # upload the process to Purview
We create an AtlasProcess object, with the typeName found earlier, the name of the asset, the inputs, outputs and its fully qualified name.
The description parameter demonstrates that once you get familiar with the PyApacheAtlas library it becomes easy to extend. AtlasProcess takes an optional dictionary of attributes, I have added a dummy description to the process. For a client, I created a function to create a more detailed description.
Another useful extension is to add column level metadata as classifications. Each column is its own entity in Purview so has a type and qualifiedName. For example, the qualified name of a column in a parquet file is the file qualified name, with ~parquet_schema//ColumnName appended. The client had column level security classifications, by using AtlasClassification and classify_entity we were able to add classifications to each sensitive column in Purview.
End Result in Purview UI
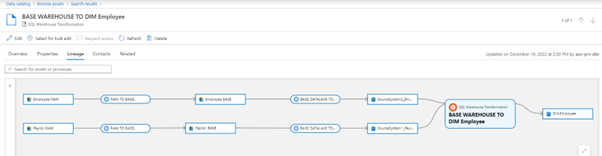
This shows the lineage of DimEmployee, originating from the two sources in the RAW layer of the datalake. I have used partial_update_entity to provide more descriptive names to the entities.
Word of Caution
Be careful about programmatically uploading purview entities or processes as they are hard to bulk-delete through the UI.
- Deleting a source from Purview does not delete its assets.
- Deleting an asset doesn’t delete its ‘related’ assets.
- Subfolders/files don’t show as related assets, so it is hard to programmatically delete these.