Self-Serve from the lake with Databricks SQL – gain better insight from your data using SQL in the databricks environment
Databricks SQL provides a self-serve data analytics platform that empowers business users to access and analyse data without the need for technical expertise, enabling them to make data-driven decisions faster and more efficiently. This short blog is aimed at those looking to better understand how they can gain insight from their data using SQL in the databricks environment.
What is Databricks SQL?
Databricks SQL is a cloud-based, SQL dedicated tool built on Apache Spark that allows users to query and analyse large amounts of data. It has continued to improve its features to provide businesses with better data capabilities since it was first released in October 2020. Key features include:
- Data Integration possible with a variety of data sources, including data lakes, data warehouses, and streaming data sources. This integration enables businesses to access and analyse all of their data in one place.
- The Databricks Unified Analytics Platform which provides a unified environment for data engineering, machine learning, and business analytics. This integration enables businesses to easily transition between different data-related tasks.
- High Performance using a distributed SQL engine that can process large volumes of data quickly. It can also handle complex queries and join operations, making it suitable for large-scale data analysis.
- Collaborative features that enable teams to work together on data analysis projects. Users can share notebooks, dashboards, and reports, and collaborate in real-time.
- Advanced security features including encryption, role-based access control, and data masking. These features help to protect sensitive data and ensure that only authorised users have access.
- Data Visualisation including charts, graphs, and dashboards that make it easy to understand and communicate data insights. There is also capability to connect into external BI tools such as PowerBI.
- Automated Machine Learning environment that allows users to build and deploy machine learning models using SQL queries. This feature makes it easy for businesses to incorporate machine learning into their data analysis workflows.
What do we mean by Self-Serve?
Databricks SQL removes the need for notebook based data tools and provides users with easy access to all of its key features through queries. Analysts, engineers & scientists can all work from the same data source to ensure a single version of the truth is maintained and can quickly make sense of their data through easy to put together dashboards with drag and drop functionality.
Connecting to the lake
There are a couple of ways to connect to the lake, however Databricks no longer recommends the option of mounting external data locations to the DBFS filesystem (used in my testing).

Python code used to mount data lake
Databricks now suggests securing access to Azure storage containers by using Azure service principals set in cluster configurations. I’d recommend following this link (https://learn.microsoft.com/en-us/azure/databricks/storage/azure-storage) which provides instructions on how to connect using the following:
- Unity Catalog managed external locations
- Azure service principals
- SAS tokens
- Account keys
Self-Serving from the lake with Databricks SQL
With a connection in place, query writing is similar to other database management systems. It supports standard SQL syntax, with some extensions to support complex data types like arrays and maps. Spark SQL is also available to query data stored in Spark data sources like Parquet, ORC, and CSV files.
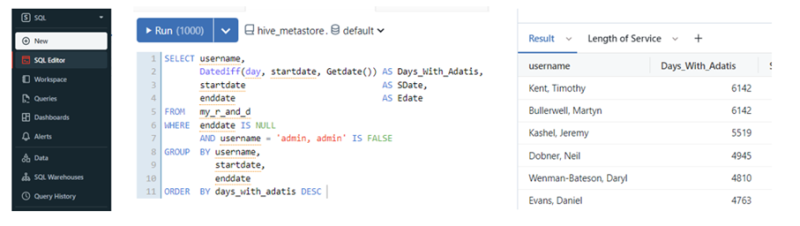
Ribbon, query editor window and results window
Dashboarding
Dashboards can then be produced (as shown below) that are great for discovering quick insight and are easily shared with stakeholders or project teams. Each visualisation has its own source query that can be written and visualised in the query editor or manually generated and edited in the ‘Dashboards’ section of the ribbon. Visuals can be formatted to customise titles and colours as well as manual editing of size, scale and position with the user friendly drag and drop approach.
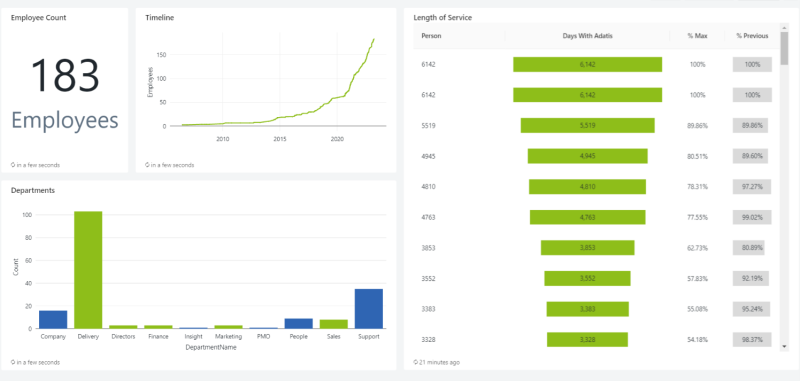
Several visualisations generated from queries on the data lake
Overall Databricks SQL is a powerful tool, useful for all data professionals to work with big data in a scalable and user friendly environment. The query editor is easy to navigate and visualisations great for quick and easy insight with simple connections into external BI tools.
If you would like learn more about our data consultancy services and how we support organisations to become truly data-driven, please get in touch.