In the constantly changing field of artificial intelligence (AI) and machine learning (ML), choosing the right model for a task is important. With the multitude of models available, ranging from OpenAI’s groundbreaking language models to custom-built solutions, developers often face the challenge of determining which model best suits their needs. Fortunately, Azure AI Studio comes in to simplify this process with the introduction of model benchmarks.
This blog will cover the impact of Model Benchmarks in Azure AI Studio. Model benchmarks play a crucial role in evaluating the performance of AI models, enabling users to make informed decisions regarding model selection and optimisation. This blog post will delve into how these benchmarks provide valuable insights into the effectiveness of different AI algorithms and their suitability for various tasks. Additionally, it will explore how businesses can leverage Model Benchmarks to enhance the efficiency and accuracy of their AI solutions, driving better outcomes across diverse domains.
Azure AI Studio is renowned for its versatility and user-friendly interface, catering to the needs of developers, data scientists, and machine learning experts alike. It offers a comprehensive suite of tools and services, facilitating the seamless transition from concept to evaluation to deployment. Now, with the addition of model benchmarks, users have a powerful tool at their disposal to review and compare the performance of various AI models. At its core, model benchmarks in Azure AI Studio provide invaluable insights into the quality and performance of different AI models. Leveraging large language models (LLMs) such as OpenAI’s renowned models and Llama 2 models like Llama-2-7b, gpt-4, gpt-4-32k, and gpt-35-turbo, the Azure AI Studio Public Preview offers users a comprehensive view of each model’s capabilities. By providing LLM quality metrics, model benchmarks simplify the model selection process, empowering users to make informed decisions. Whether you’re exploring text generation, sentiment analysis, or any other AI application, having access to performance metrics can make all the difference in choosing the right model for the job.
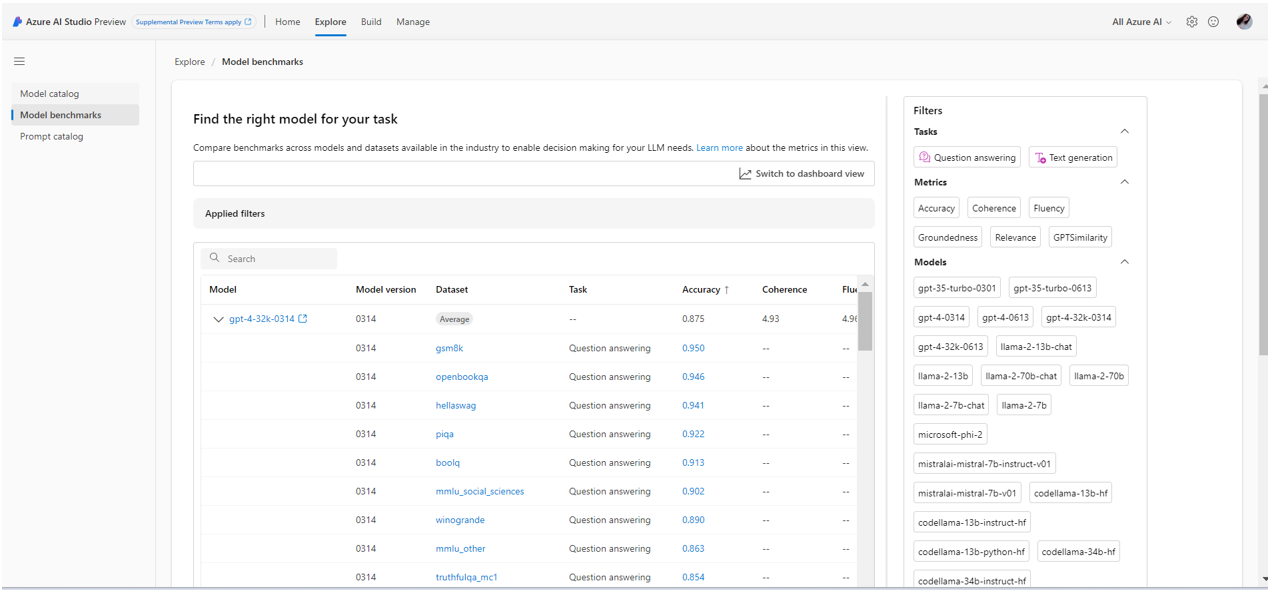
List presentation of the model benchmarks interface
How does it work?
You might lean towards selecting a model that has been evaluated on a specific dataset or task. In Azure AI Studio, you can compare benchmarks across various models and datasets commonly used in the industry to determine which one best suits your business scenario. You can explore models available for benchmarking on the Explore page within Azure AI Studio.
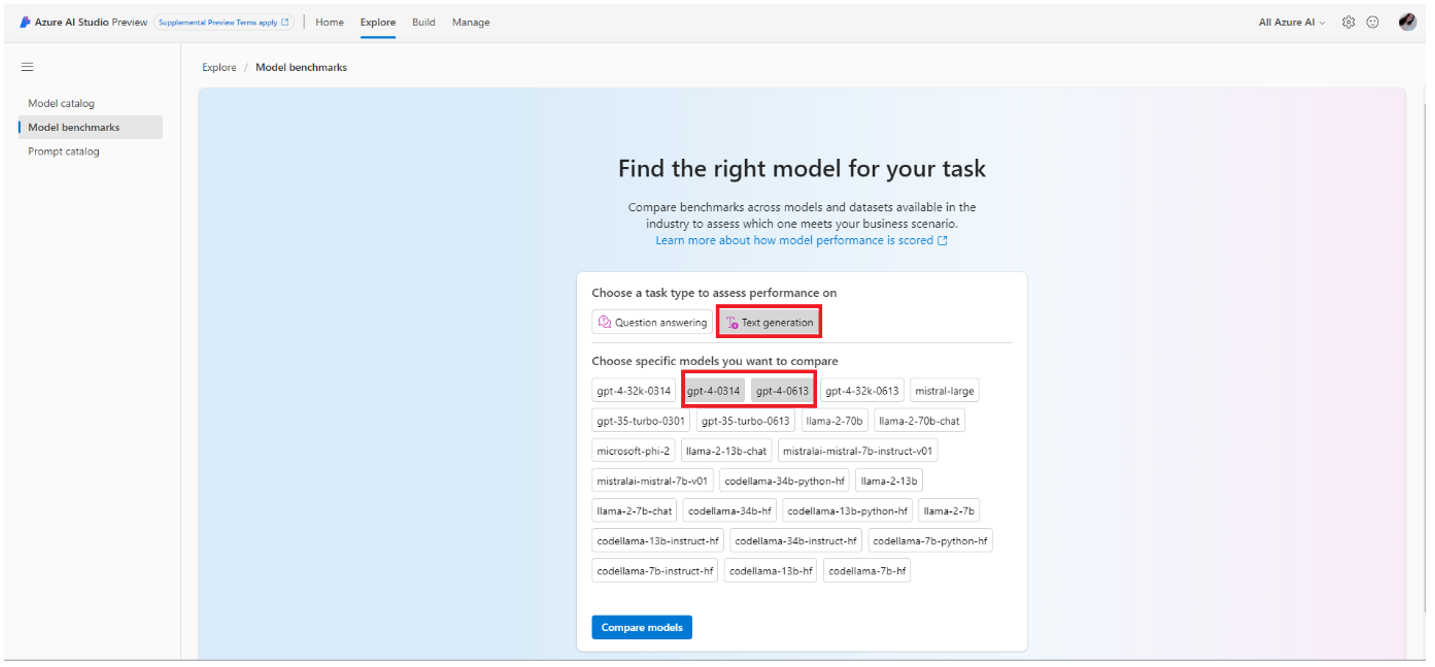
Select the models and tasks you want to benchmark, and then select compare.
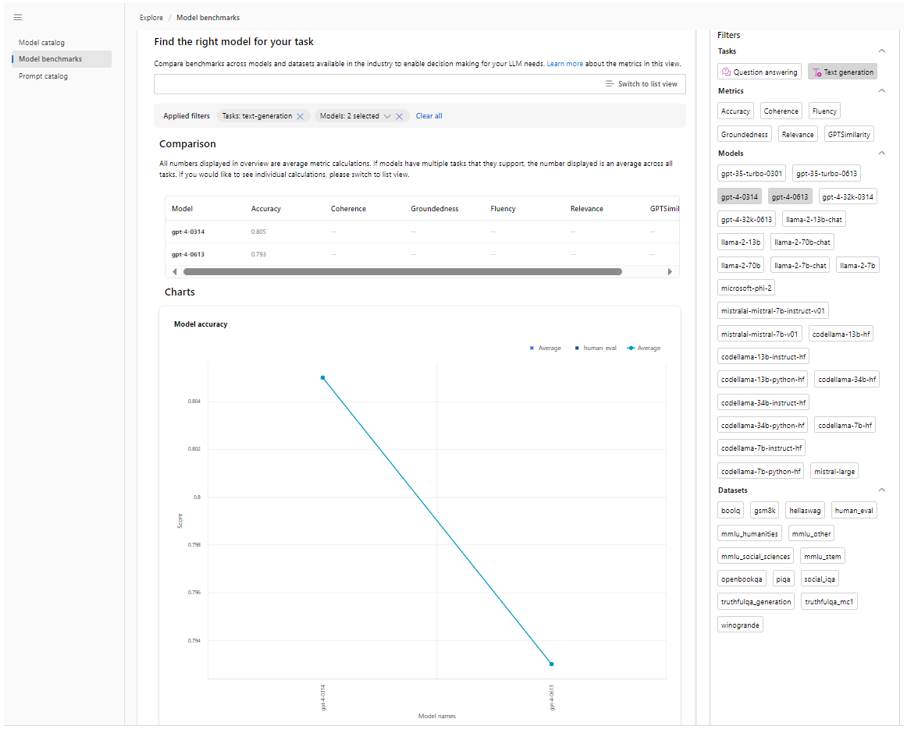
View for comparing model benchmarks experience
The model benchmarks assist in making well-informed decisions regarding the suitability of models and datasets before commencing any task. These benchmarks consist of a carefully curated list of the most effective models for a given task, determined through a comprehensive comparison of benchmarking metrics. Currently, Azure AI Studio solely offers benchmarks that focus on accuracy. The benchmarks receive regular updates to integrate additional metrics and datasets into existing models, alongside the inclusion of newly introduced models into the model catalogue.
How are the scores computed for benchmarks?
To generate the benchmarks, we rely on three main components:
- A base model sourced from the Azure AI model catalogue.
- Publicly available datasets.
- Metric scores for evaluation.
The benchmark results are sourced from public datasets that are widely utilised for evaluating language models. These datasets are typically hosted on GitHub repositories, overseen by the creators or caretakers of the data. Azure AI evaluation pipelines retrieve the data directly from its original sources, extract prompts from each example row, generate model responses, and then calculate accuracy metrics that are relevant to the task at hand. This meticulous process ensures that the benchmark results are accurate and reliable, providing users with valuable insights into the performance of different AI models.
Prompt construction follows the guidelines set out by the dataset’s introduction paper and industry standards. Generally, prompts consist of various examples of complete questions and answers, known as “shots,” to help the model understand the task better. These shots are formed by selecting questions and answers from a subset of the data reserved for evaluation. This method ensures that the prompts adequately prepare the model and contribute to accurate evaluations, resulting in more dependable benchmark results.
Display options available in the model benchmarks
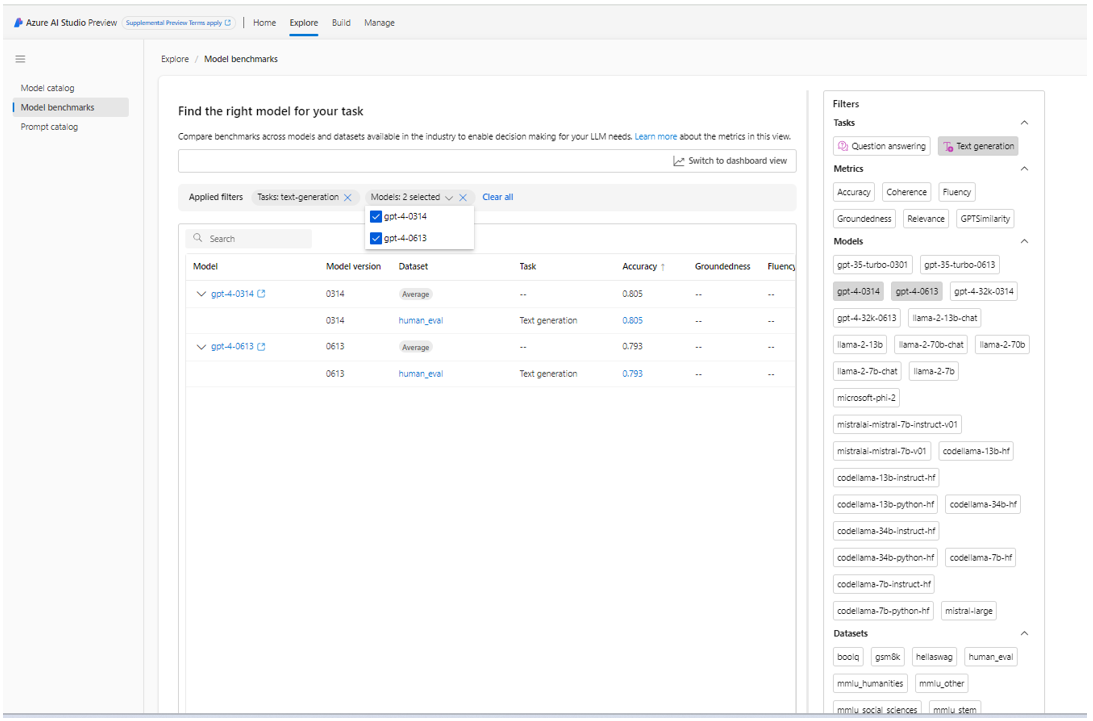
These benchmarks offer both a list view and a dashboard view of the data for convenient comparison, along with informative details explaining the significance of the calculated metrics:
- Model name, description, version, and aggregate scores.
- Benchmark datasets (such as AGIEval) and tasks (such as question answering) that were used to evaluate the model.
- Model scores per dataset.
Additionally, you have the option to filter the list view based on model name, dataset, and task.
The dashboard view enables you to compare the performance scores of multiple models across different datasets and tasks. You can visually assess models side by side (horizontally along the x-axis) and compare their scores (vertically along the y-axis) for each metric.
To switch to the dashboard view from the list view, simply follow these steps:
1.Choose the models you want to compare.
2.Click on “Switch to dashboard view” located on the right side of the page.
What metrics do we compute?
Within the model benchmarks experience, we primarily calculate accuracy scores. These accuracy scores are provided at both the dataset (or task) level and the model level. At the dataset level, the score represents the average accuracy metric computed across all examples within the dataset. The accuracy metric utilised is typically an exact-match, except for the HumanEval dataset, which employs a pass@1 metric. Exact match involves comparing the model’s generated text with the correct answer according to the dataset, reporting a score of one if the generated text matches the answer exactly, and zero otherwise. Pass@1 measures the proportion of model solutions that successfully pass a predefined set of unit tests in a code generation task. At the model level, the accuracy score is derived from the average dataset-level accuracies for each model.
Conclusion
Model Benchmarks in Azure AI Studio provide valuable insights and comparisons for evaluating the performance of different AI models. This feature enables users to make informed decisions when selecting models for their specific tasks, enhancing the efficiency and effectiveness of AI implementation. With access to comprehensive benchmarking data, businesses can optimise their AI solutions and drive better outcomes in various domains.