This blog was authored by: Jose Mendes | 19th November 2024
Microsoft Ignite 2024 is currently taking place in Chicago from November 19th to 21st. As always, the Data and AI community is eagerly anticipating the latest announcements from Microsoft. With FabCon Europe having taken place less than two months ago, there was some scepticism about Microsoft’s ability to unveil any major new Fabric features. However, they still had a couple of aces up their sleeve, ready to be revealed at just the right moment.
In this blog, I’ll start by sharing my key Fabric announcements, followed by an overview of the newly released Fabric Databases, now in public preview.
If you would like to check the full list of announcements, you can read Arun’s blog, the Fabric November blog and the Power BI November Feature Summary blog.
Key Announcements
OneLake catalog
Microsoft Fabric aims to provide a unified experience for data teams looking to reduce the cost and effort involved in data integration, governance, and security. Tackling this complex challenge will require multiple iterations before reaching the ultimate “nirvana” solution.
With the OneLake data hub, users could discover, manage, and utilise data across the organisation. It offered a single location to explore available assets but lacked essential governance functionalities. To address this gap, Microsoft has redesigned the OneLake data hub, creating the next iteration: the OneLake Catalog. This enhanced version allows users to continue leveraging existing features for exploring Fabric items while also introducing new capabilities, such as insights into data quality and compliance, and recommendations for optimising the data estate.
To elevate these capabilities, Microsoft recommends connecting to Microsoft Purview. This enables users to among other capabilities, apply Information Protection sensitive labels to control access to Fabric items or use Data Loss Prevention to detect the upload of sensitive data.
Ideally, I’d like to see the OneLake Catalog be further enhanced with the long-awaited OneLake Security feature, providing a single interface to explore, govern, and secure all Fabric items (currently, each Fabric item storing data has its own security model). While we’re not quite there yet, the future looks promising.
Open mirroring
Microsoft has been gradually extending mirroring capabilities for databases and data warehouses, including; Azure SQL Database, SQL Managed Instance, Snowflake, Azure Databricks Unity Catalog, and Cosmos DB. This new functionality allows businesses to access data in near-real time without implementing complex ingestion processes. It not only reduces costs associated with data ingestion but also streamlines data access, whether in its raw format or as transformed, enriched, and aggregated star schema entities.
Recognising the potential of this feature, Microsoft has further expanded it with a new capability called “open mirroring.” This addition allows data providers and applications to virtualise their data into a mirrored database within Fabric, enhancing accessibility and integration options. You can find more information here.
Fabric CI/CD Tools
Microsoft has been developing products for years, but somehow, CI/CD and Git integration often seem to take a back seat, leaving data engineers and developers eagerly waiting for the release of these features. I’m pleased to see that Microsoft is making strides in this area, gradually expanding the number of services that support REST APIs, Git integration, and deployment pipelines — specifically Real-Time Intelligence artefacts, Dataflow Gen2, and Copy Job. However, two critical improvements are still needed:
1) More robust and scalable deployment pipelines to eliminate the need for manual, creative workarounds
2) Service principal support across all REST APIs
Workspace monitoring
As your data estate expands, disparate and complex data inevitably accumulates, making it challenging to consolidate under a single view. In PaaS environments, we can enable diagnostic settings to converge logs and workload metrics in Log Analytics. But how can this be achieved in Fabric? The new workspace monitoring feature offers a seamless, consistent experience for admins and developers by storing collected information in a read-only Eventhouse KQL database. Users can diagnose issues affecting their services using KQL and boost productivity by saving queries as reusable query sets, ready to share with colleagues or for future use.
Fabric Databases Overview
When Fabric was launched, many counterpart PaaS services were reflected in the new platform (e.g. Azure Data Factory = Fabric Data Factory, Azure Synapse Spark Pools = Fabric Data Engineering, Azure Synapse Analytics Dedicated SQL Pools = Fabric Data Warehouse). In some cases, you could build a complete data platform using only the available Fabric features.
However, a few essential services were missing, which required Azure solutions, such as Azure SQL Databases. The Fabric Warehouse is excellent for analytical purposes but is not a suitable choice for transactional workloads, which typically involve high volumes of concurrent writes, updates, and deletions. This is why Fabric Databases were introduced—the first database engine in Fabric built upon the SQL Server engine and equipped with security features like cloud authentication and database encryption. Fabric Databases are ideal to build AI apps, however, can also take part on metadata-driven data platforms built.
Telefónica Tech Data & AI can rapidly deliver value to customers using a framework accelerator. A key component of this framework is an Azure SQL Database, which stores metadata that supports the data processing flow. Integrating this service with a Fabric data platform introduced architectural complexity. However, this can now be simplified with the Fabric Database. The following sections will demonstrate how to quickly create a new database, configure Git integration, and deploy an existing SQL project using VS Code.
Create Fabric Database
Creating a new database is straightforward. Once the item is available in your tenant, you’ll have access to a new Databases experience. From there, simply select SQL Database and provide a unique name. Like the Lakehouse and Warehouse, once created, you’ll have access to the SQL Database, where you can define, query, and update data, along with SQL analytics endpoints and the default semantic model.
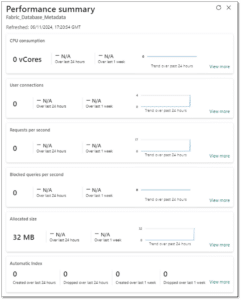
This experience feels distinct compared to the Fabric Warehouse. Although this blog doesn’t cover it, you can bring data into the database via Data Pipelines or Dataflow Gen2. Additionally, you’ll have access to core KPIs that provide a performance summary, with the option to explore further using the performance dashboard.
Configuring Git Integration
The representation of a SQL Database in Fabric includes a SQL project and metadata reflecting the Fabric object. Although it’s possible to manually generate the SQL project, the metadata files can only be generated when committed to source control.
To add the Database to source control, configure the Git Integration in the workspace. Any existing item will be automatically synced with Git.
When inspecting the repository in Azure DevOps, we can see the following items.
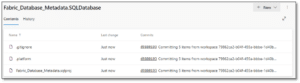
The .platform file contains the metadata for Fabric, whereas the .sqlproj file represents the SQL project declaration. Only projects with the .platform file can be deployed via the Fabric interface.
Managing the Database in VS Code
Fabric Databases projects can be managed using VS Code. Azure Data Studio or SSMS. These tools offer a level of depth, flexibility, and tooling that can significantly enhance productivity and efficiency, especially for tasks that go beyond basic querying and require more granular control over database operations, performance tuning and source control.
Before opening the project, you need to install the SQL Server (mssql) and SQL Database Projects extension. Once that’s done, you can open the Fabric project using the Fabric UI or directly in the IDE.
When selecting one of the above options, you are presented with the connection strings.
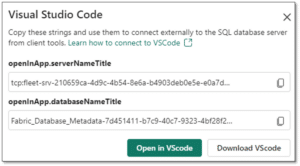
With this option, you will be using the SQL Server extension and make changes directly to the database in Fabric. To commit the changes to source control you need to use the Fabric interface.
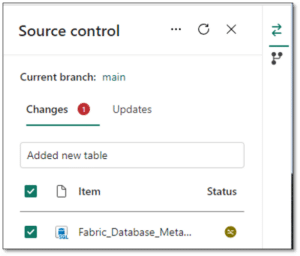
Although this workflow is functional, it’s not ideal, as it requires switching between the local IDE, the Fabric UI, and Azure DevOps. It offers limited flexibility for Git operations and changes to the database are immediately reflected. Cloning the repository and working locally allow us to make changes and validate them without impacting the workload on the database instance. When the repository is cloned, we can start adding all the relevant SQL objects and use the SQL Database Project extension to build the project and validate the changes before commiting to source control.
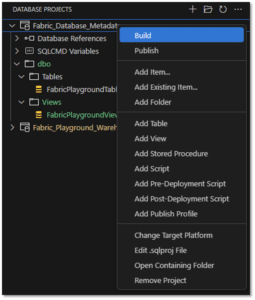
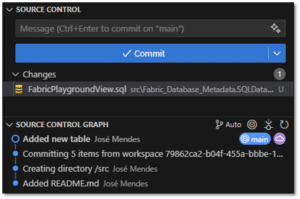
Once the changes are committed, we can see a warning in the Fabric UI mentioning there are pending updates from Git.

After syncing the workspace, we can successfully see the new object available in the Database.
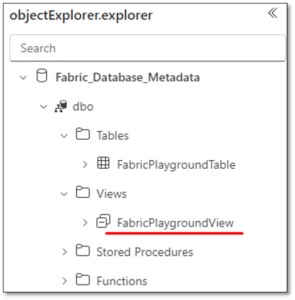
Taking it to the next level
So far, we have gone through the basics, but how can we elevate our experience? Can we take an existing SQL project and deploy it directly to the Fabric Database? Can we use Azure DevOps Pipelines to automate the database deployments?
It’s not possible to deploy a project built for a different target platform due to differences in the SQL Project. However, if we copy the existing scripts to a Fabric SQL Project, then we can successfully build it and publish it.
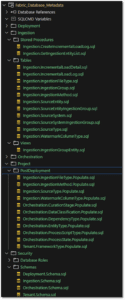
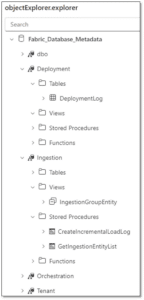
To publish the project, we can either perform the operation manually in VS Code or automate it using Azure DevOps Pipelines (stay tuned for the next blog, where I’ll cover the deployment process).
If you would like to learn more about Microsoft Fabric and how Telefónica Tech can help you, please get in touch.