Microsoft Healthcare Accelerator for Fabric
Microsoft released the Healthcare Data Solutions in Microsoft Fabric in Q1 2024. It was introduced as a “A game-changer for healthcare data analysis” by Umesh Rustogi, General Manager of Microsoft Health and Life Sciences Data Platform.
Microsoft Fabric is a unified platform that bundles services, apps, and connectors under a single umbrella, providing users with the tooling to meet all data and analytics needs.
The Healthcare Data Solutions are built on top of this robust service offering. The solution is aimed at users who are looking for a powerful tool to integrate and transform Healthcare data. In addition, users can run real-time analytics, data science workloads and meet business intelligence needs without compromising the privacy and security of their data.
In this introductory guide, users will learn everything needed to get started with the Healthcare Accelerator and translate data from disparate data sources into coherent, visually immersive, and interactive insights.
- What is the Healthcare Accelerator?
- How does the Healthcare Accelerator work?
- Benefits of using the Healthcare Accelerator
- Basic Concepts & Terms
- How to Install the Healthcare Accelerator
- Exploring the Healthcare Accelerator’s Capabilities
- Next Steps
What is the Healthcare Accelerator?
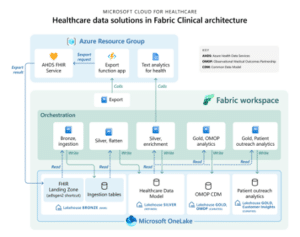
The Microsoft Healthcare Accelerator leverages Microsoft Fabric to bring together structured, unstructured, clinical, imaging and medical device data within OneLake. The accelerator supports various healthcare standards, such as FHIR® and DICOM®.
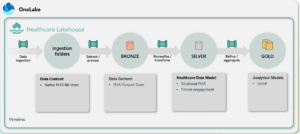
The Accelerator deploys a Healthcare Data Lake House in which resources are arranged in accordance with the medallion architecture to improve the shape and quality of the data as it progresses through each layer of the architecture from Bronze, to Silver, and finally Gold.
In addition to this, the Accelerator integrates well with other Microsoft services such as Microsoft Dynamics 365 and Microsoft Power Platform to facilitate “care management and achieve better outcomes throughout the patient journey”.
Image taken from Microsoft Learn
How does the Healthcare Accelerator work?
Broadly speaking, the Accelerator ingests FHIR data, then refines, enriches, standardises the data before it is made available for analysis and exporting. The Accelerator is modular, allowing users to deploy artefacts to support their particular use case. We’ll describe these capabilities in more detail.
- Data Ingestion – The solution includes a FHIR export service, which allows users to ingest FHIR complaint clinical data, which lands within the FHIR landing zone in OneLake as raw ndjson – newline delimited JSON files. At this point the data is ready for processing.
- Data Refinement & Enrichment – Several notebooks are included for data processing and refining within the bronze, silver, and gold layers. The data is flattened and tabularised from JSON format to allow the usage of SQL – the language of choice for data engineers and analysts. The Accelerator also facilitates Data Science workloads. More specifically, users can carry out text analysis and entity extraction against unstructured clinical notes by making calls to Azure AI Text Analytics for Health.
- Data Standardisation & Analytics – The solution also supports Observational Medical Outcomes Partnership (OMOP) analytics which begins by standardising FHIR data into a common data model using the open community standards of the OMOP. This paves the way for analytics. Through the provided notebooks, users can “construct statistical models, conduct population distribution studies, and utilise Power BI reports to visually compare various interventions and their effects on patient outcomes.”
- Data Export –The solution also integrates with Dynamics 365 Customer Insights. The highly nested structure of the FHIR data means it must be prepared before it can be used within Dynamic 365 for patient or member outreach. The solution facilitates the flattening of this data and thus removes any compatibility issues. As a result users can easily connect Dynamics 365 Customer Insights to the patient data stored within OneLake.
Benefits of using the Healthcare Accelerator
- Uses the industry common data model OMOP which standardises the data, making it easy to structure, store, share and use.
- Integrates with AI services to enrich the data and provide an extra layer of intelligence.
- Supports FHIR, as well as DICOM and MedTech, allowing users to work with different types of unstructured data, such as imaging and device data.
- Integrates with the Microsoft Power Platform allowing users to interact with the data using low-code/no-code platform tools.
Basic Concepts & Terms
- FHIR (Fast Healthcare Interoperability Resources) – provides a robust, extensible data model with standardised semantics that all FHIR-compliant systems can use interchangeably.
- Azure API for FHIR– is a single service that provides a managed platform for exchanging health data using the FHIR standard (mainly structured data).
- Azure Health Data Services – is a set of managed API services based on open standards and frameworks that enable workflows to improve healthcare and offer scalable and secure healthcare solutions. Supports FHIR, as well as DICOM, which allows it to work with different types of data, such as imaging and device data (unstructured data).
- healthcare#_msft_bronze lakehouse– stores the source data in its original state without any transformations.
- healthcare#_msft_silverlakehouse – data is sourced from the bronze lakehouse and undergoes refinement, validation and enrichment.
- healthcare#_msft_gold_omop lakehouse– data is sourced from the silver lakehouse and is aggregated and standardised. The data has reached a high enough level of quality to make it suitable for analysis and export.
- healthcare#_msft_config_notebook– is the global configuration notebook. See More.
- healthcare#_msft_raw_bronze_ingestion– this notebook is used to ingest data into delta tables in the healthcare#_msft_bronze lakehouse. See More.
- healthcare#_msft_bronze_silver_flatten– flattens FHIR data as it moves from the healthcare#_msft_bronze lakehouse and into the healthcare#_msft_silver lakehouse. See More.
- healthcare#_msft_silver_sample_flatten_extensions_utility– performs further operations on data within the healthcare#_msft_silver lakehouse by tabularising deeply nested extension data within the silver lakehouse. See More.
- healthcare#_msft_fhir_export_service notebook– uses the bulk $export API provided by Azure Health Data Services to export FHIR data to an Azure Storage container on a recurring basis. See More.
How to Install the Healthcare Accelerator
Getting started with the Healthcare Accelerator is relatively straightforward especially as the process is well documented. The worked examples covered in the next section “Exploring the Healthcare Accelerator’s Capabilities”, use the sample data provided by the solution.
Exploring the Healthcare Accelerator’s Capabilities
In this section we’ll look at:
- Sample Data (Optional Package)
- Healthcare Data Foundation (Mandatory Package)
- Unstructured Clinical Notes Enrichment (Optional Package)
- OMOP Analytics (Optional Package)
- D365 Customer Insights – Data Preparation (Optional Package)
We’ll briefly mention the Sample Data & D365 Customer Insights – Data preparation packages. However, we’ll cover the other packages in a more detail.
Sample Data (Optional Package)
You can utilise the FHIR export service and Microsoft Fabric OneLake to efficiently integrate FHIR data from Azure Health Data Services (AHDS). In addditon to the AHDS you need to provision and configure an Azure Function App to communicate with the AHDS. Please consult the Microsoft Documentation for more information.
We’re going to make use of the sample data provided by the solution to quickly get started. There are two datasets which get deployed to OneLake, (1) FHIR sample data (2) OMOP Vocabulary data. We can access the data locally using the file explorer as show below, please see details on how to get this setup on your machine.
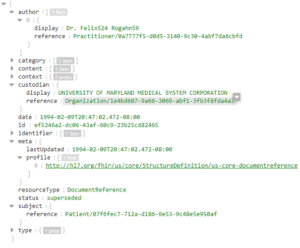
Here is preview of a sample record within the DocumentReference entity which stores unstructured clinical notes. Incidentally, we’ll make use of this entity when carrying out text analysis and entity extraction with Azure AI Text Analytics for Health.
Healthcare Data Foundation (Mandatory Package)
The Healthcare Data Foundation provisions the below artefacts to the Fabric workspace – a mixture of Lakehouse objects and notebooks which form the Medallion Architecture. Please note that resources are prefixed with the workspace name (GreenFabric – in this instance). The config notebook has a dependency on provisioning the Azure Health Data Services (AHDS) within the Azure Portal. Please ensure that the key vault resource created as part of the AHDS deployment is referenced within the config notebook.
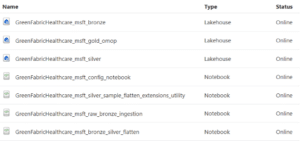
Before running any notebooks, users are required to use Fabric runtime version 1.1, please see instructions on how to change the configuration.
The GreenFabricHealthcare_msft_raw_bronze_ingestion notebook allows us to ingest data into delta tables in the GreenFabricHealthcare_msft_bronze Lakehouse. Below is a view of the underlying files for the account entity. We can use the SQL Endpoint to begin interacting with the data using T-SQL.

The GreenFabricHealthcare_msft_bronze_silver_flatten notebook uses the SilverIngestionService module in the library to flatten FHIR resources in the GreenFabricHealthcare_msft_bronze Lakehouse and to ingest the resulting data into the GreenFabricHealthcare_msft_silver Lakehouse. This can take up to 20mins to complete.
![]()
The GreenFabricHealthcare_msft_silver_sample_flatten_extensions_utility notebook allows users to parse child elements that represent additional information. This results in the following delta tables:
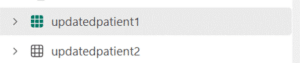
The updatedpatient1 table takes the following shape

Unstructured Clinical Notes Enrichment (Optional Package)
This notebook calls the Azure AI Language’s Text Analytics for Health service to extract key FHIR entities and add structure to unstructured clinical notes (contained within the DocumentReference table) for analytics. Through machine-learning intelligence we’re able to extract and label relevant medical information from a variety of unstructured texts such as doctor’s notes, discharge summaries, clinical documents, and electronic health records. For details on how to setup Azure Language Services, please consult the documentation.
The output from the Natural Language Processing analysis is stored in the following tables within the GreenFabricHealthcare_msft_silver Lakehouse:
- nlpentity: Contains the flattened entities extracted from the unstructured clinical notes. Each row is a single term extracted from the unstructured text after performing the text analysis.
- nlprelationship: Provides the relationship between the extracted entities.
- nlpfhir: Contains the FHIR output bundle as a JSON string.
The below is an example of the unstructured text that gets passed in the call to Azure AI Language’s Text Analytics Services.
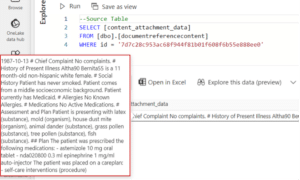
The nlpentity takes the follow shape for the record in question.
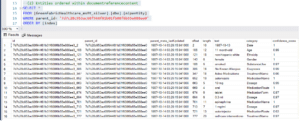
The nlprelationship takes the follow shape.
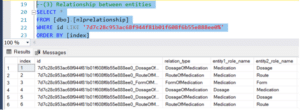
OMOP Analytics (Optional Package)
This capability prepares data for standardised analytics through the Observational Medical Outcomes Partnership (OMOP) open community standards. This capability has a direct dependency on the Healthcare Data Foundations.
There are prerequisites for using this package:
- Ensure you have the OMOP reference dataset downloaded – deployed as as part of the Sample Data Package.
- Ensure there’s a OMOP Data warehouse – deployed as part of the Healthcare Data Foundations Package.
- Readthe Background Information.
The GreenFabricHealthcare_msft_silver_omop notebook transforms resources in the GreenFabricHealthcare_msft_silver Lakehouse into the OMOP common data model within the OMOP Lakehouse (Gold Layer).
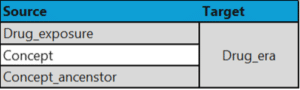
The GreenFabricHealthcare_msft_omop_sample_drug_exposure_era notebook demonstrates the process of generating records into the drug_era table within OMOP Lakehouse, primarily for exploratory purposes. The Drug_era entity is defined within the OMOP Standard “as a span of time when the Person is assumed to be exposed to a particular active ingredient”. The DrugEraGenerator module truncates and loads data into the this table, using the three tables listed below as source tables.
The GreenFabricHealthcare_msft_omop_sample_drug_exposure_insights notebook demonstrates an exploratory analysis on the drug_era table. The analysis generates a histogram displaying patients’ secondary drug exposures to active ingredients, stratified by gender and age for a specific year.
Dynamics 365 Customer Insights – Data preparation – (Optional Package)
This capability enables users to connect Dynamics 365 Customer Insights to OneLake within Fabric. With this connection, users gain the capability to easily create patient or member lists for outreach purposes. Stepping through this capability is beyond the scope of this blog, there is sufficient instruction provided by the Microsoft documentation.
Next Steps
In order to productionise the Accelerator, a degree of customisation is expected. Anything from modifying the notebook configurations to adding entirely new notebooks. Its unlikely that users will use this solution straight out of the box. Moreover, users would need to setup orchestration pipelines to allow the solution to run relevant notebooks on a scheduled basis to capture deltas within the data. This requires the use of Fabric Data Factory pipelines to ingest the FHIR data into OneLake as well push the data through the Medallion Architecture, instead of using Azure Data Factory. The former carries a few limitations which need to be well understood in order to make the solution fully operational.
Implementing metadata driven orchestration pipelines is a baseline for most ETL workloads and the Healthcare Accelerator is no exception. This is the most efficient way to manage and orchestrate numerous datasets. Telefónica Tech is well positioned to help with this requirement, we offer a Rapid Microsoft Fabric Proof of Concept through which we can help onboard your FHIR data within Microsoft Fabric. We can also provide additional capabilities and support for when you’re ready to take the solution from a PoC to an MVP using our proprietary Data & AI Microsoft Fabric Framework. Please get in touch to learn how we can add value on


