Convolutional neural networks and computer vision holds the potential to completely revolutionize the safety and efficiency of human beings when they move about, work, communicate, and even help overcome natural limitations or deficiencies in our own ability to see.
The first successful convolution networks were developed in the late 1990s by Professor Yann LeCunn for Bell Labs and since then researchers and the media have named convolutional neural networks (CNN’s) as the super stars of neural networks in deep learning.
Convolutional neural networks are a class of deep neural networks that are most commonly applied in computer vision as they are able to perform relatively complex tasks with images. They are usually composed by a set of layers that can be grouped by their functionalities.
Seamless transportation with 100% accident-free autonomous vehicles, high-speed drones and delivery vehicles operating without risk of collision and the end of blindness and vision loss are just some of the key areas in which CNN enabled computer vision will play a huge role.
Based on feedback, I’ve decided to split this post into two. One post will focus on the operations that help CNN’s to identify and classify objects and the second one will similarly go through and explain the recurrent neural networks.
The assumption here is that you’ve read the first three parts of this series and are already familiar with traditional neural networks. If not, I highly recommend reading the first three parts (Part 1, Part 2, Part 3)
This post will outline the example of a CNN that is capable of recognizing trees in images. A tree, depending on its type, will have certain characteristics like its branches, foliage, trunk, etc. Those characteristics will help the model determine if a tree is present in the image or not. As such we’ll deal with 2D convolutions on images. The concepts covered will also apply for 1D and 3D convolutions, but may not correlate directly.

The main advantages of a CNN architecture is that it can successfully capture the spatial and temporal dependencies in an image through the application of relevant filters, while also reducing the number of parameters involved.
A CNN can be trained to better understand the sophistication of an image by reducing it into a form which is easier to process, without losing any of the important features.
Convolution Layer
The name itself “convolutional neural network” indicates that the network uses a mathematical operation called convolution, which is a specialised kind of linear operation that slides a filter on a matrix of an image in order to extract from it some pre-determined characteristics.
The matrix of an image is just a matrix containing all the pixel values for each colour channel of that image.
Here’s the grayscale pixel values of our tree image;

What is a filter and can we apply multiple filters to the same image?
A convolution filter slides over all the pixels of the image taking their dot product. The filter is made up of multiple kernels for each input channel, in the case of images there will be 3 channels, RGB.
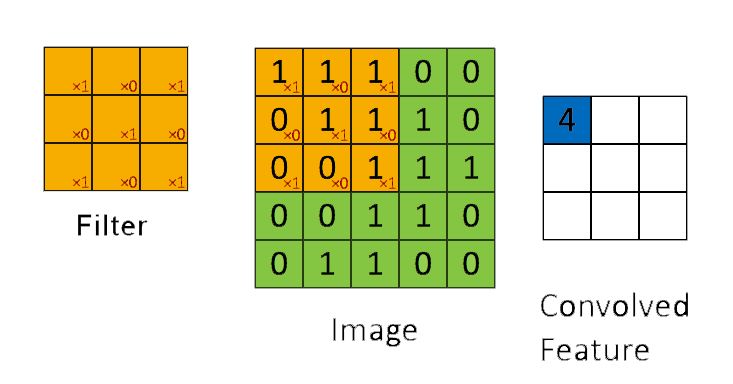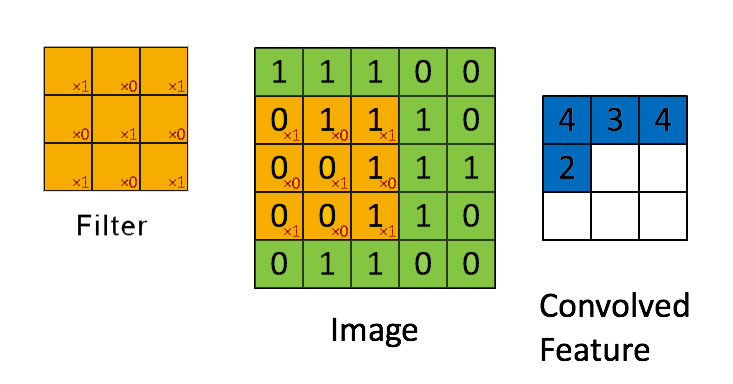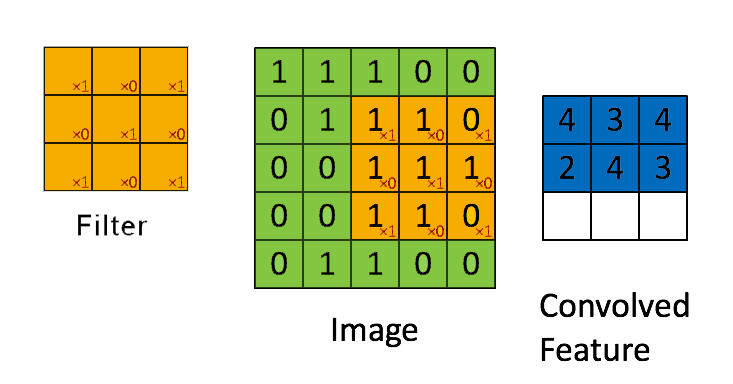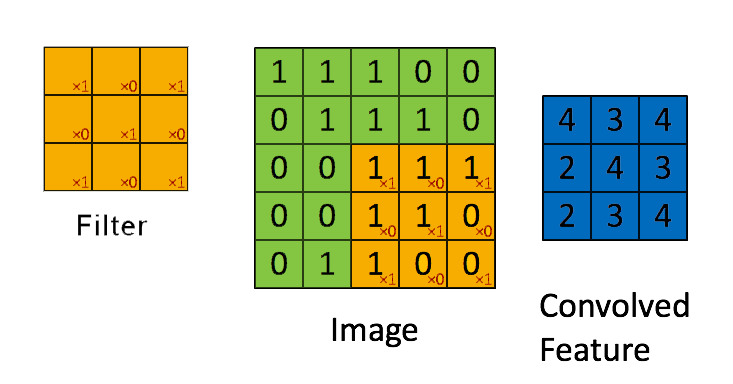
In practice instead of applying just one filter, we can apply multiple filters with different values on the same image one after another so that we can get multiple feature maps.

In other words, a convolution filter helps to create a feature map by extracting features such as edges, colour, spots, etc from the input image.
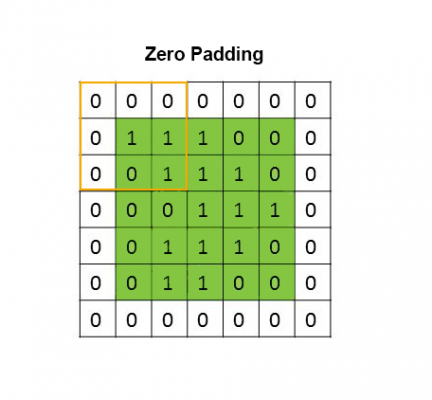
Depending on the chosen filter size, some filters may reduce the dimension of an image. In order to prevent the dimensions from shrinking and to extract all features of an image, including details that might be in corners where the filter will overlap over a pixel only once, padding is used.
Without padding, a pixel on the corner of an image overlaps with just one filter region, while a pixel in the middle of the image overlaps with many filter regions. Hence, the pixel in the middle affects more units in the next layer and therefore has a greater impact on the output.
Usually a CNN contains multiple convolutional layers, the first layer captures the Low-Level features such as edges, colour, gradient orientation, etc, while the other added convolutional layers will build on top of the low-level features and detect objects or larger shapes in the image, thus approaching a more human level understanding of an image.
Combining the features highlighted by those filters; such as edges of trees, branches, green colour and brown tusk, a CNN model will be able train on tree images and then detect and classify trees in any image.
Therefore, when building a CNN, it’s important to consider the number of convolutions, the number and kind of filters to use, whether padding is necessary and which activation function to use.
Keep in mind that the more filters are used, the more details will be extracted, the more numerous the parameters of the model will be and therefore a longer training time but with a better degree of accuracy.
This is important when designing an architecture which is not only good at learning features but also is scalable to massive datasets.
Pooling Layer
CNNs can get computationally intensive once the images reach dimensions, say 8K (7680×4320).
In order to decrease the computational power required to process big images, a dimensionality reduction operation called Pooling is often used.
The addition of a pooling layer after the convolutional layer provides an approach to down sample feature maps by summarizing the presence of details in patches of the feature map without losing any details that are critical for ensuring a good classification.
The pooling layer operates upon each feature map separately to create a new set of the same number of pooled feature maps.
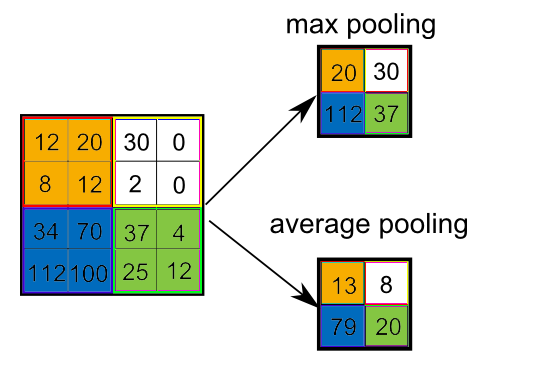
There are two types of Pooling: Max Pooling and Average Pooling.
- Max Pooling returns the maximum value from the portion of the image covered by the filter.
- Average Pooling returns the average of all the values from the portion of the image covered by the filter.
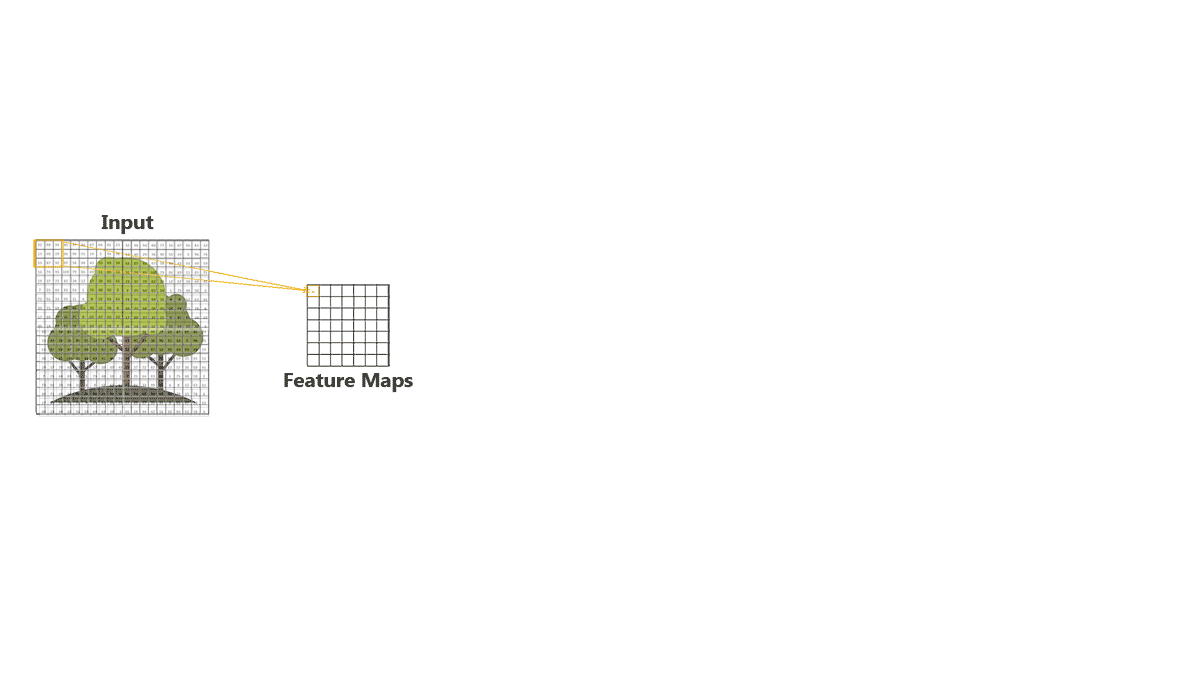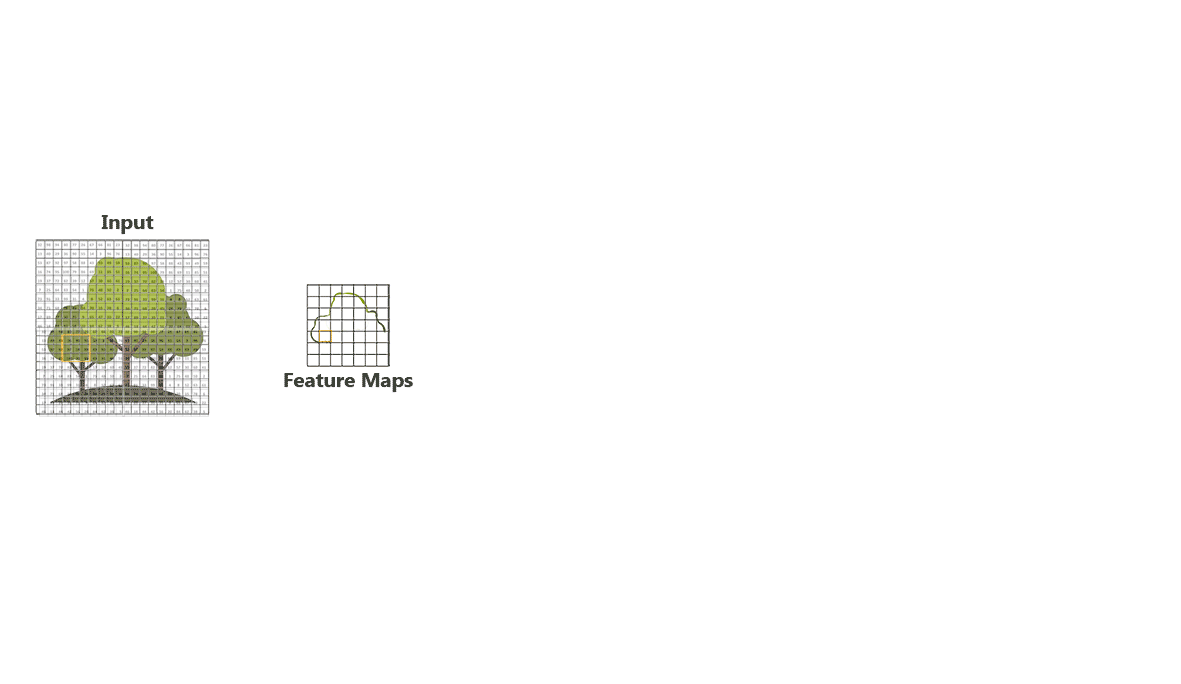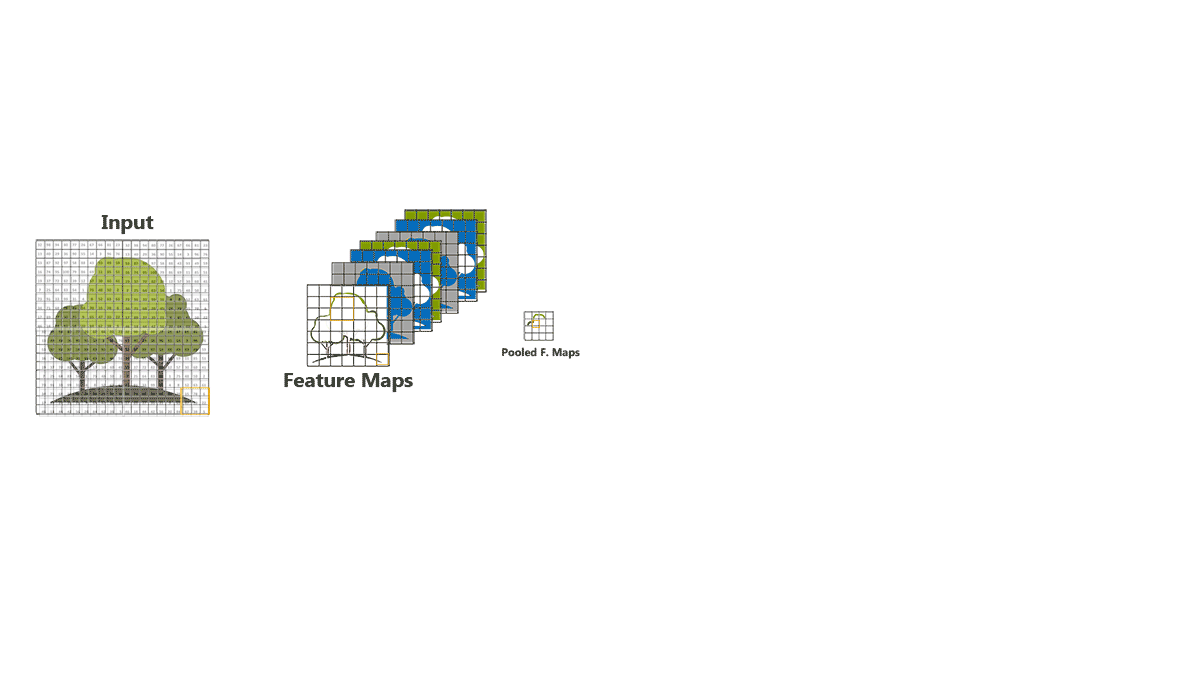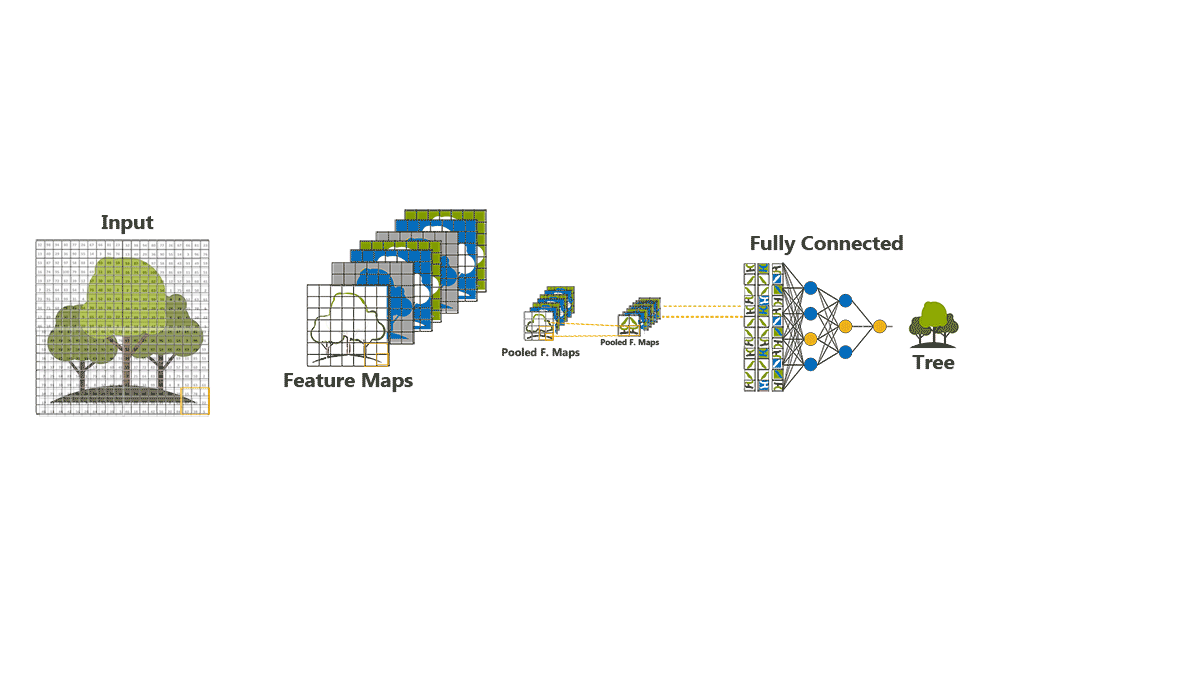
Classification (Fully Connected Layer)
Adding a Fully-Connected layer allows the model to learn the non-linear combinations of the high-level features represented by the output of the previous convolutional layers.
Fully connected layers are usually added as the last few layers of a CNN. These layers would essentially act in a similar way to the layers in a traditional neural network except that the inputs received would be output of the last pooling layer.
The output of convolution/pooling is flattened into a single vector of values, each representing a probability that a certain feature belongs to a label. For example, if the image is of a tree, features representing things like branches or foliage should have high probabilities for the label “t”.
The FCL will then perform the classification based on the features extracted by the convolutional layers.
Some of the best CNNs architectures that have millions of trainable parameters and can perform incredibly well across many different image processing tasks are the ResNet models which are incorporated by major corporations such as Microsoft in their off-the-shelf products like cognitive services, VGG models, YOLO and googles inception models.
Up to this point, this series has covered what a single neuron is, how it processes information forward, how single neurons are grouped into layers to form an artificial neural network, the error correction algorithms of gradient descent and backpropagation, the supervised and unsupervised approach to learning as well as deep and reinforcement learning.
This post adds on that knowledge base the details and intricacies of convolutional neural networks, leaving recurrent neural networks and generative adversarial networks to be covered in the next two posts.
The next part of this series will cover in a similar fashion the recurrent neural networks.
What are your thoughts? Can you think of any application for convolutional neural networks or computer vision in your industry?
The following video made by Denis Dmitriev shows a 3D representation of how neural networks operate, including convolutional neural networks.
As always, the following resources will come in handy in acquiring a deeper and more practical understanding of computer vision:
CS231n: Convolutional Neural Networks for Visual Recognition.
Practical Convolutional Neural Networks: Implement Advanced Deep Learning Models Using Python by Md. Rezaul Karim, Mohit Sewak, and Pradeep Pujari: One stop guide to implementing award-winning, and cutting-edge CNN architectures
Computer Vision: Algorithms and Applications by Richard Szeliski: This book is online, free, and is authored by a stereopsis, structure from motion, Microsoft Kinect, expert. http://szeliski.org/Book/
Learning OpenCV by Bradski and Kaehler: This book explains the theory while teaching you how to code in OpenCV. It is very practical and is a must-have to do anything useful in computer vision.
OpenCV tutorials: https://docs.opencv.org/master/d9/df8/tutorial_root.html