During the early hours of each morning you usually receive a file containing the latest batch of records e.g. transactions, but one day that file does not arrive (shock!). You enquire with the provider, whom admit to fault and assure you that the issue is in hand. Upon investigation, the problem is rectified and you are informed that the file will arrive with the next batch the following morning. For some, this may ring fear as they did not foresee a situation where multiple files would be present at the time of execution, but you are a great data engineer and so you have remained calm. Your cunning use of SQL Server Integration Service’s (SSIS) ForEach component beautifully caters for the processing of multiple files; “as many as you like” you may brag, and so it makes sense to be aware of the Data Factory (ADF) version of this technique.
Tip
Before you consider applying this technique, please may I point out that, wherever possible, event driven solutions should be considered first. Some examples of event driven solutions are:
- Where the originating process responsible for producing the source files also has the scope to trigger your ADF pipeline upon the creation of each file, and pass the metadata in as parameter values.
- The source file is landed into an Azure Storage Account where you will be able to take advantage of ADF’s Event Trigger and the trigger variables.
Objective
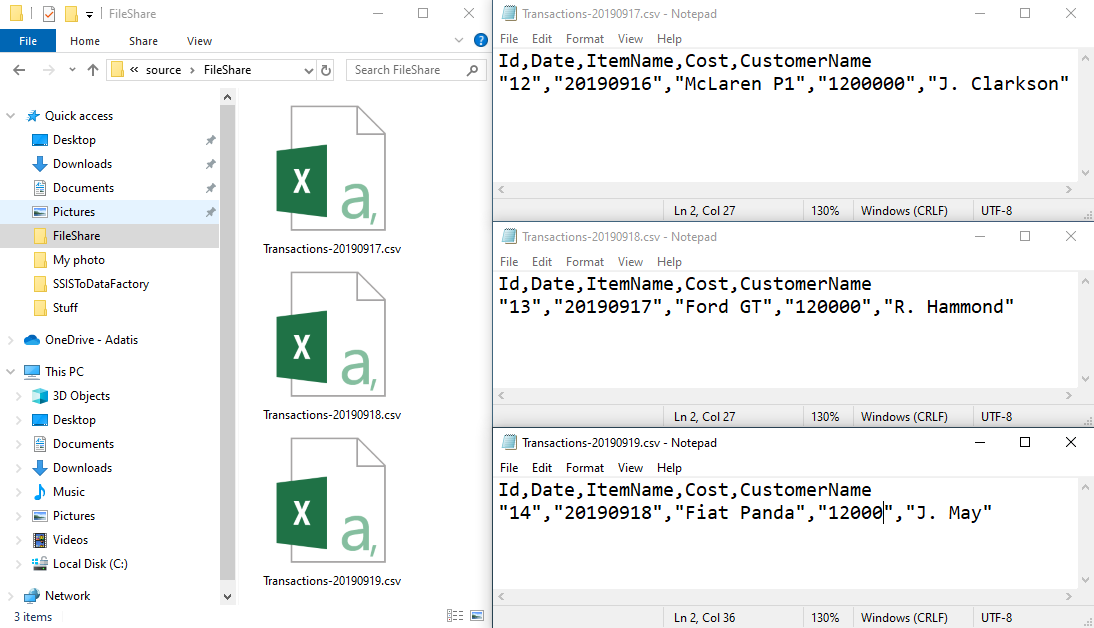
In this demonstration, I will show you how to loop through files within a local file share. I have created 3 test .csv files where the file type and file date are included within the file name. The aim is to:
- Copy the files from file share to an Azure Storage Account
- Structure the destination directories to align with the file date e.g. Transactions/2019/09/17/
Steps already taken
- ADF created and deployed within an Azure subscription
- Connection for File Share created within ADF
- Microsoft Integration Runtime installed and configured with the ADF key on my local machine
- Azure Storage account created and deployed. I have used Account kind: BlobStorage, but any Account kind will be sufficient.
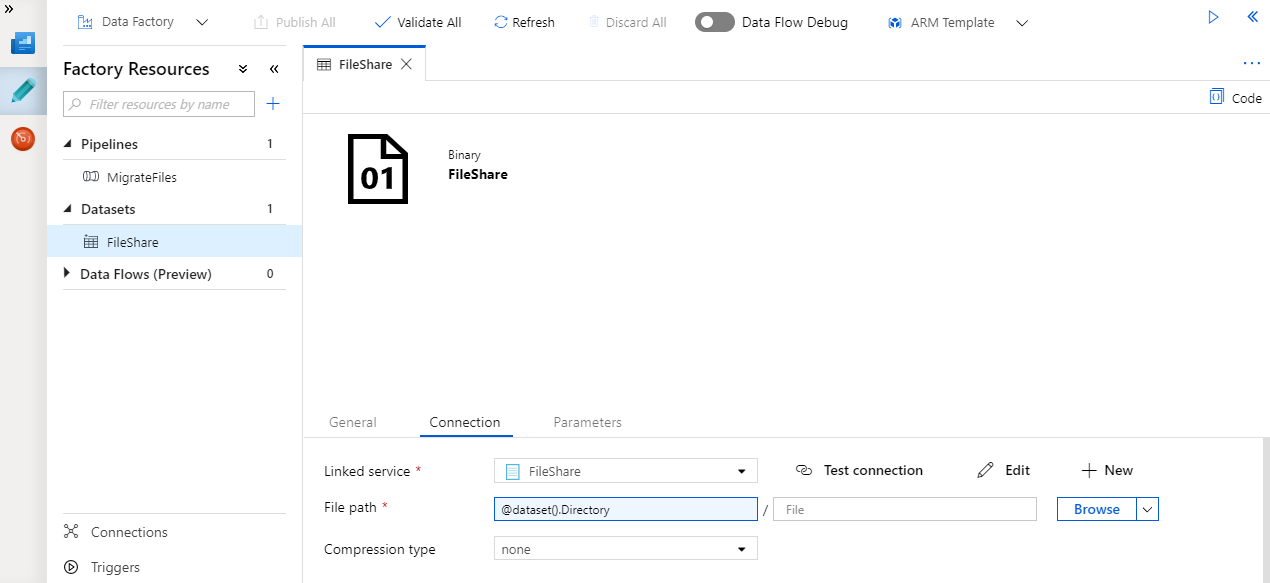
Create Datasets
Starting with the FIleShare dataset, I have used
Create Pipeline