When we are thinking about data platforms, there are many different services and architectures that can be used – sometimes this can be a bit overwhelming! Data warehouses, data models, data lakes and reports are all typical components of an enterprise data platform, which have different uses and skills required. However, in the past few years a new architecture has been rising; the data lakehouse. This is an architecture that borrows ideas and concepts from several different areas, which we will be exploring in greater detail in this blog.
A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.
Looking at the Databricks’ definition of a data lakehouse above, we can see lots of terms and concepts that could be confusing to those new to data platforms. Luckily, we will be exploring these in a lot more detail!
This blog will start by introducing some core concepts which are required to fully understand the context and requirement for a data lakehouse. Following this, we will cover a typical existing data platform architecture, and identify issues with it. Finally, we will examine the technologies that enable data lakehouse architectures, the data lakehouse architecture itself and the benefits of using this design.
Core Concepts
Different Types of Data
When we think about data, we can divide it into three broad categories; structured, semi-structured and unstructured. The categories are as follows:
- Structured – This is tabular data, which can be divided into rows and columns. This is typically what people traditionally consider data, and the structure of the data can be thought of as a schema.
- Unstructured – This is data stored without a schema, in its native format. Examples of this would be images, videos and audio files.
- Semi-Structured – This sits between the two former categories, where a structure can be derived from the data. Examples of this would be HTML and JSON files.
ACID Transactions
A key concept within data services is of ACID transactions. A transaction represents a change within a database – for example in a database of customer contact details, one may want to update a customer’s home address when they have moved houses. The acronym ‘ACID’ is used to allow a database to be both recoverable and for multiple programs to access the database at the same time, and covers the standards required for a high-performing database that can handle lots of operations. The acronym stands for the following:
- Atomicity – A transaction is treated as either fully executing, or not executing at all. This avoids a transaction partially executing and corrupting the data within the database.
- Consistency – A transaction will only make changes to the database in a predictable way, to avoid any unintended changes within the database.
- Isolation – In a database, lots of users will be making transactions at the same time. Isolation means that the final state of several transactions applied at the same time is equivalent to transactions being executed one after another.
- Durability – A completed transaction’s changes will be committed to the database, even in the case of a system crashing.
Data Platform Components
The most well-established section of an enterprise data platform is the data warehouse. This is a single source of truth within an organisation, combining structured data from different data sources and making it available for analysts to query and make reports with. A data warehouse also has the ability to query large amounts of structured data, making use of massively-parallelised processing techniques to complete this. The downside of this is that data warehouses are often expensive to operate, and it can be difficult to structure a data warehouse to best support an organisation effectively (further information around BEAM and Kimball modelling can be found here).
While a data warehouse works well with structured data, it is less-suited for handling unstructured and semi-structured data. This is where the requirement for a storage repository with large amounts of data in its native format can be established, which is the function of a data lake. This can be almost thought of as an enterprise-wide file system, where files can easily be stored and shared between different data services (they have much more powerful functionality than just this, read more about it here). The ability to store and utilise unstructured and semi-structured data means data scientists find data lakes particularly useful.
Data Lake-Data Warehouse Architecture
Modern Data Warehouse-style data platforms often use a data lake and data warehouse-based architecture. If we imagine raw data being ingested into the data lake and need it to be served to users in a Kimball data model, the pathway of raw data through to being available would be as follows:
- Raw data is landed in the data lake at an initial area of the data lake, which we have named ‘Raw’ in this example.
- The data is then cleaned and prepared as required for use later in the data platform, and then stored in a different area of the data lake, which we have named ‘Base’ in this example.
- The prepared data is then ingested into the data warehouse, being passed into a staging area.
- Data is transformed into the required data model and served to users who require it.
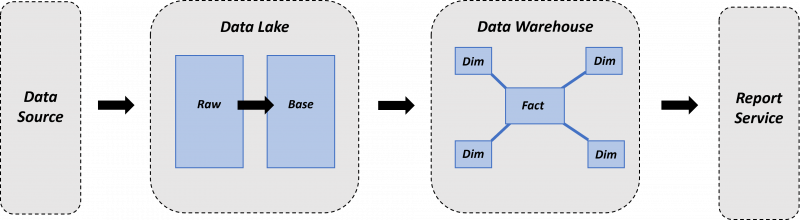
A simple data lake-data warehouse architecture that could be used in a data platform.
Need for Change
While data warehouses and data lakes both have their places in enterprise data platforms, they both have strengths and weaknesses. Data lakes are much more flexible in terms of the data that they can store, while data warehouses allow tabular data to be stored and reported upon very efficiently. Data warehouses are ACID transaction compliant, however data lakes are not (changing data within a data lake is not always straightforward). They also vary in pricing – data warehouses are typically much more expensive than data lakes. From here, we can see that the ability to combine the best features of both services could provide a one stop shop for an enterprise’s analytical needs.
Data Lakehouse
The data lakehouse architecture design provides a framework to build the analytical power of a data warehouse on top of the cheap storage and flexible structure that a data lake provides. Several open-source and other cloud technologies have been created that allow for this framework to be created, such as ADLS Gen 2, Delta Lake and Azure Databricks/Azure Synapse Analytics. These are detailed and discussed below.
Azure Data Lake Storage Gen 2
Azure Data Lake Storage (ADLS) Gen 2 is a Microsoft Azure service that allows for data lakes to be created in the cloud. This combines concepts from two separate services, Azure Blob Storage and ADLS Gen 1. Azure Blob Storage allows for the storage of massive amounts of data as binary large objects – ‘Blobs’ for short. This allows for unstructured data to be stored easily, in an enterprise-scalable service.
ADLS Gen 1 is an Apache Hadoop file system, which allows for data to be stored in a Hadoop Distributed File System (HDFS). Without diving into the technical details of how HDFS works, it allows for distributed data processing to be completed with extremely large data volumes. The feature that allows this is a ‘hierarchical namespace’, providing a file system for the distributed processing to work efficiently on top of.
ADLS Gen 2 is a combination of the cheap storage provided by Azure Blob Storage, alongside the distributed data processing provided by ADLS Gen 1. The service is therefore well suited for creating a data lake, as massive volumes of data that one would find at an enterprise-level can then be processed efficiently.
Delta Lake
Delta Lake is an open-source technology that allows the blob objects stored within the data lake to be grouped together into tables via a governance layer, allowing for ACID transactions to take place within the data lake while complex queries are taking place. While the mechanism for how Delta Lake works is fairly detailed (find more here), it can be thought as tracking which blob objects in the data lake form a table, and a specific version of a table. This unlocks the ability to form a Data Lakehouse architecture on top of ADLS Gen 2.
The core entity within Delta Lake is the Delta Table, which is saved within the ‘delta’ format. A table is formed of two separate concepts within the data lake itself. These concepts are:
- The data objects themselves, which contain the contents of the table.
- The transaction log, which defines the objects that are part of a specific version of a table. The transaction log also provides checkpoints, which is a summary of the log up-to a certain point to allow for optimal performance.
A final important concept within Delta Lake to cover here is the immutability of data objects and transaction logs within the table. For example, if the user wanted to modify a row within a Delta Lake table, rather than the object (X1) containing the row being directly modified, a copy of the object (X2) is instead taken and modified. The transaction log will then create a new version of the table, which will have the modified copy of the object (X2) used instead of the ‘old’ version of the object (X1).
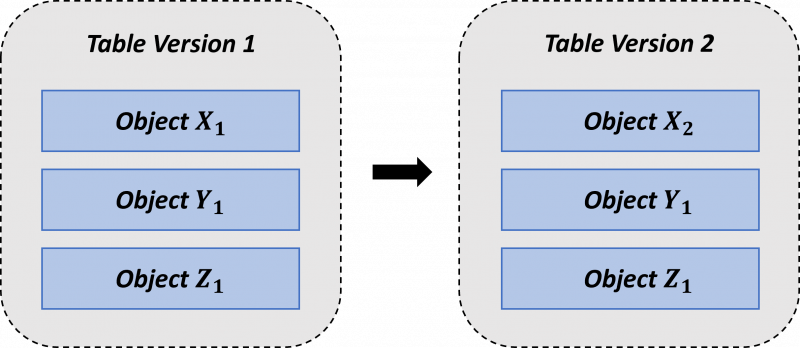
Diagram to show how Tables work within Delta Lake.
Azure Databricks and Azure Synapse Analytics
Once we have our data lake created, we need to have a service to actually create, read and modify Delta Tables. Two services that provide this ability are Azure Synapse Analytics and Azure Databricks. Both of these services can be interacted with via a notebook-based environment in multiple languages, with connectivity to both ADLS Gen 2 and many other Azure services. Both of these services are frequently used in enterprise-level data platforms, so hopefully will provide a familiar tool to readers (more information on Azure Databricks and Azure Synapse Analytics).
Data Lakehouse Architecture
By combining these different services together, a simple data lakehouse architecture can be derived. If we imagine raw data being ingested into the data lake and we need it to be served to users in a Kimball data model, the pathway of raw data through to being available would be as follows:
- Raw data from multiple sources is ingested into the data lake for use.
- Convert the data from native format into Delta Tables, using Delta Lake.
- Convert the Delta Tables into a data model.
- Serve the data model through to users.
This architecture avoids the need for transferring and storing duplicate data in multiple services, which introduces unnecessary complexity and cost into a data platform’s architecture. The architecture also allows the cheaper storage available within ADLS Gen 2 to be leveraged, allowing large amounts of data to be stored and transformed into a data model, at lower cost.
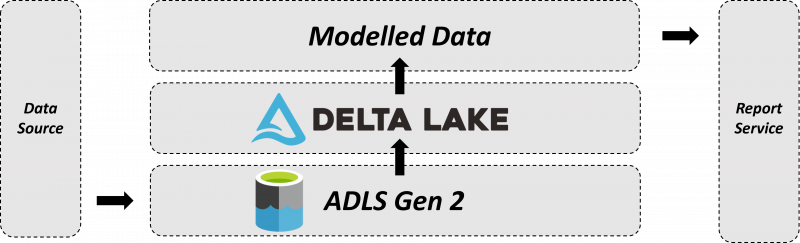
A simple data lakehouse architecture that could be used in a data platform.
Conclusion
Within this blog, we have had a look at what a data lakehouse is, some of the technologies that can be used to create a data lakehouse and the existing architectures it can be used to replace. Hopefully this has been helpful in improving your understanding – if you have any thoughts, feel free to get in touch!