This blog was authored by: Naiden Borimechkov Mendes | 29 October 2024
No matter the size of your organisation, managing and governing data efficiently has become a priority.
This has become increasingly challenging with the growing complexity of data management across different teams, tools, and environments. As a result Databricks introduced Unity Catalog, a powerful feature designed to simplify and centralise data governance within the Databricks ecosystem.
In this blog post, we will explore the key features and functionalities of Unity Catalog including how it differs from traditional Hive Metastore governance, and its technical capabilities.

What is Unity Catalog?
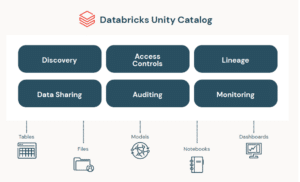
Unity Catalog is a unified governance solution for Databricks that centralises access control, auditing, data lineage, and data discovery capabilities across Databricks workspaces. Prior to Unity Catalog, data management within Databricks was fragmented, with each workspace managing its own metadata, user permissions, and access control. This decentralised approach often led to inconsistencies in data governance, making it challenging to apply uniform policies and manage access across different workspaces.
Unity Catalog introduces a centralised metastore that is shared across multiple workspaces. This allows administrators to define and enforce access control policies, audit data usage, and track data lineage across the organisation—all from a single location.
Key Features of Unity Catalog
- Centralised Access Control
One of the most significant improvements Unity Catalog brings is centralised access control. Instead of managing permissions at the individual workspace level, administrators can now define and enforce policies across all workspaces connected to the same metastore. Unity Catalog supports ANSI SQL for granting and revoking permissions, making it easy for administrators to manage access across different data assets such as tables, views, and functions.
- Data Lineage
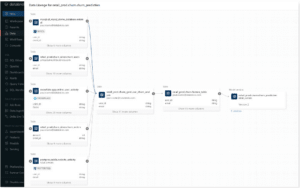
Data lineage is a critical feature of Unity Catalog that helps organisations visualise how data flows across different datasets and processes within the platform. By tracking and displaying the entire data pipeline, from raw data to processed insights, Unity Catalog provides transparency into data transformations and dependencies. This feature is especially useful for troubleshooting issues, auditing data usage, and ensuring data integrity.
- Auditing and Data Discovery
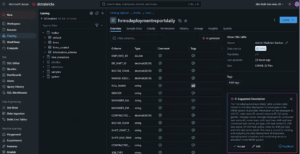
Unity Catalog automatically captures user-level audit logs that record access to data. This feature ensures that organisations can track who accessed what data and when, helping meet compliance and regulatory requirements. Additionally, Unity Catalog includes data discovery capabilities, allowing users to search for data assets using metadata tags and comments. I recently used this feature to tag PII data columns in the data entities, ensuring that we handle those entities with extra care and making it easier for other teams to quickly locate the PII data they need.
- Support for Cloud Object Storage
While the Hive Metastore was designed to work with the Hadoop Distributed File System (HDFS), Unity Catalog is optimised for modern cloud environments. It supports cloud object storage such as Amazon S3 and Azure Data Lake Storage, allowing organisations to leverage cloud infrastructure for storing and managing their data assets. This flexibility makes Unity Catalog an ideal choice for those looking to build scalable and cloud-native data architectures.
How Unity Catalog Works
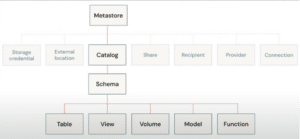
Now you know what Unity Catalog is, this section will focus on how the tool works. It operates on a three-level namespace that consists of catalogs, schemas (also known as databases), and tables. This structure provides a logical way to order data and allows for better separation between different layers of data processing.
- Catalog: The top-level container that groups related schemas and tables.
- Schema: A collection of tables and views within a catalog.
- Table: The actual data storage entity, which can be a managed table (Delta format) or an external table (various formats like Parquet, CSV, JSON, etc.).
In addition to these objects, Unity Catalog also supports volumes for storing non-tabular data and machine learning models, making it a versatile solution for managing different types of data.
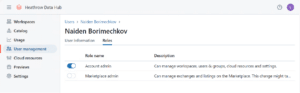
Administrative Roles in Unity Catalog
Unity Catalog introduces several key administrative roles that help manage access and governance:
- Account Admin: This role is responsible for creating and linking metastores to workspaces, as well as managing storage credentials and assigning Metastore Admins.

- Metastore Admin: This role has full control over the metastore, including the ability to manage catalogs, schemas, and tables.
- Workspace Admin: This role is responsible for managing users, groups, and permissions within individual workspaces.
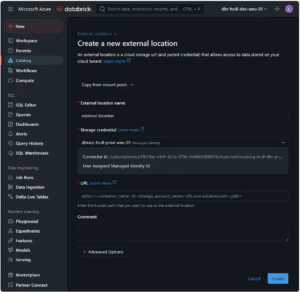
Integration with External Data Sources
Unity Catalog allows organisations to integrate with external data sources, such as Snowflake and MySQL, through a feature called Lakehouse Query Federation. This feature enables users to query external databases without needing to move the data into Databricks. For example, you can create a connection to a Snowflake data warehouse and run queries directly from Databricks, allowing for seamless data analysis across multiple platforms. External connections can be easily added to the catalog using the following step:
A Comparison: Unity Catalog vs. Hive Metastore
The introduction of Unity Catalog marks a significant shift from the traditional Hive Metastore approach. In the Hive Metastore, each workspace managed its own metadata, which limited the ability to enforce consistent governance across different environments. Unity Catalog, on the other hand, offers a shared metastore that spans multiple workspaces, allowing organisations to centralise their governance efforts.
Additionally, while the Hive Metastore uses a two-level namespace (database and table), Unity Catalog introduces a three-level namespace (catalog, schema, and table). This hierarchy provides more granularity and flexibility when organising and referencing data assets, making it easier to manage large-scale data environments.
Conclusion
Unity Catalog is a powerful tool for centralising data governance and simplifying data management in Databricks. With its robust features like centralised access control, data lineage tracking, auditing, and data discovery, Unity Catalog provides customers with the tools they need to manage and govern their data efficiently. By supporting modern cloud environments and integrating with external data sources, Unity Catalog also offers the flexibility needed for today’s data-driven companies.
In future posts, we’ll dive deeper into how to set up and configure Unity Catalog in your Databricks environment. If you have any questions, feel free to reach out to me on LinkedIn. Otherwise, stay tuned for more tutorials and tips on getting the most out of Unity Catalog.
Naiden Borimechkov
Data Engineer at Telefónica Tech – Data & AI