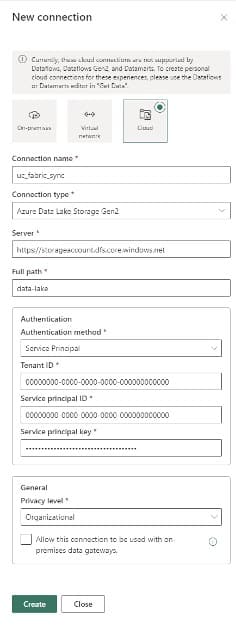
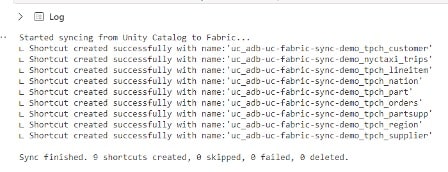
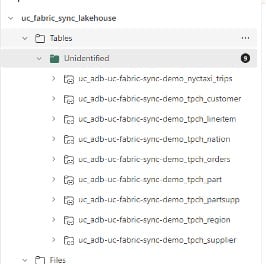
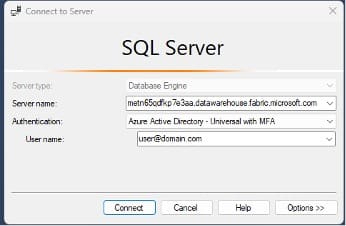
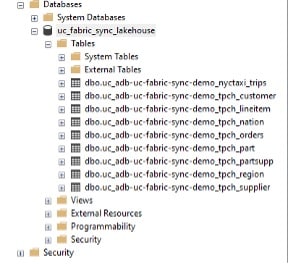
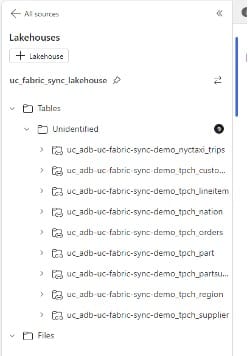
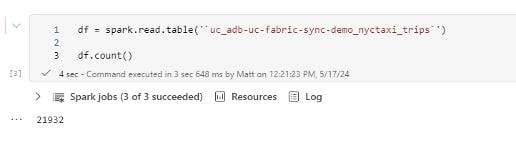
Now you have a quick, simple way to migrate data from Databricks to Fabric. One caveat is that this only works with unity catalog external tables and overrides any security policies applied, thus meaning additional security policies would need to be implemented in Fabric.
For production use it’s recommended to use Databricks OAuth to connect to the databricks API instead of using a PAT.
As the Fabric workspaces need to have an active capacity running, this only becomes a cost-effective solution where an existing PowerBI P1 license already exists. In theory, it could reduce Databricks compute costs as you don’t need a Databricks cluster running to read the data.
In an alternate scenario where you don’t hold a P1 license, a Fabric capacity would have to be provisioned to allow the creation of the shortcuts and to read the data, thus possibly leading to a higher platform running cost vs using a Serverless SQL Warehouse in Databricks.
Source: Integrate Databricks Unity Catalog with OneLake – Microsoft Fabric | Microsoft Learn