Recently, Microsoft announced its new data analytics solution Microsoft Fabric, that promises to revolutionise how organisations approach their Data & AI projects. Let’s have a look at what is available in public preview.
If you missed the announcement, you can read the highlights here: Microsoft Fabric. If you don’t have the time, then I can tell you in a nutshell that Fabric is like Azure Synapse Analytics on steroids. Using a lake-centric software as a service (SaaS) approach, Fabric offers data integration, data engineering, data warehousing, data science, real-time analytics, and business intelligence, all hosted in one platform.
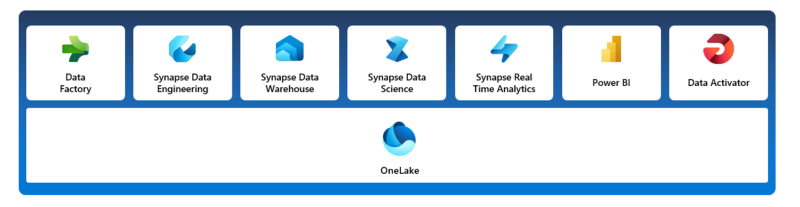
The vison behind Fabric is that organisations no longer need to spend time with the configuration and management of the infrastructure. Instead, different teams can use a single solution that promises to take 5 seconds to sign-in and 5 minutes to deliver value. To achieve this, Microsoft placed in a single location well known offerings like Power BI, with new versions of PaaS services like Data Factory and Azure Data Explorer, and brand new concepts like OneLake and Data Activator.
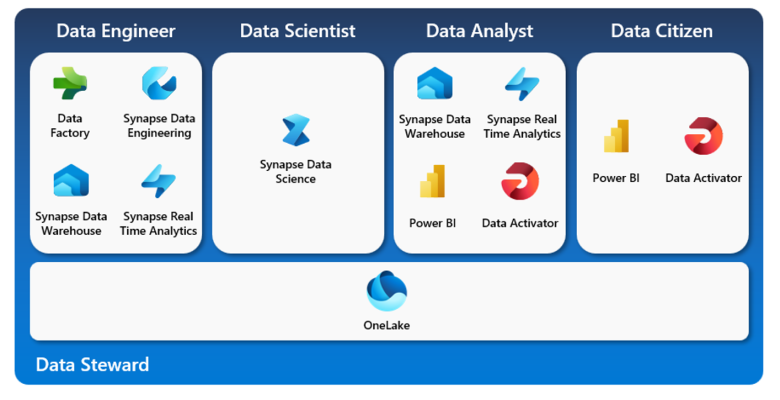
For the first time, we are seeing a solution that truly serves not only the data engineers, data scientists and data analysts, but also looks to empower data citizens and data stewards in an accessible and simple way. The image below roughly aligns the different services in public preview (note Data Activator is not yet available) to a persona, however, more tech saving data citizens will also have the opportunity to use some of the other tools to explore new and existing data.
As with many new products, there’s always a mix of excitement and uncertainty. Much could be covered, however, today I’m keeping it simple and will start the excitement journey by talking about the core workloads released for the public preview.
OneLake
OneLake is the OneDrive for data and the structure that underpins Fabric. Built on top of ADLS Gen2, it comes by default with every Fabric tenant and simplifies the user experience, without ever needing to understand infrastructure concepts or require an Azure account.
OneLake is designed to be the single source of truth for all the analytics data, whether it is being consumed by a lakehouse, a data warehouse, a KQL database or a Power BI report. As it has the same underlying data lake, the tenant admins can take advantage of the out of the box governance, like data lineage and catalog integration, and unify management and governance policies across all teams and domains in the organisation.
One Lake has 4 key concepts:
Shortcuts
Just like the shortcuts available in any OS, this feature allows easy access to the data without having to move or duplicate information unnecessarily, whether the data is stored in the same or different workspace, within a storage account in Azure or AWS. Although it is only a reference to the data, OneLake makes it look like it is stored just like any other local source and can be reused multiple times without ever having to duplicate it.
Open Access
Although the backend is not accessible or visible to the frontend user, OneLake data, including shortcuts, can still be accessed by any application or tool that supports ADLS Gen2 APIs and SDKs without having to provision additional configurations.
One Copy
Traditionally, the data would be stored in the application storage, eg. SQL Server or KQL in proprietary databases. You would then have to use T-SQL to load data into tables or Spark to load and transform data to parquet for example. Interoperability was just a dream, until OneLake arrived. By storing data in the open Delta Lake format, the different analytics engines can now access the same data using different languages.
One Security
Using Azure Active Directory (AAD) authentication, data within OneLake can be secured in two layers by: 1) Setting access to specific sections of the lake, such as a workspace; 2) Restricting access to a specific query engine, without direct access to OneLake.
Data Factory
Just like with Synapse Pipelines, Microsoft decided to add a third option to ingest, transform and orchestrate the data movement and created another version of Data Factory. The user experience is slightly different from the predecessor and the UI is meant to be more user friendly. As it is in its early stages, many connectors and activities are still missing, but Microsoft’s aim is that eventually this becomes the default option when it comes to low-code transformation (Dataflows) and complex ETL and Data Factory workflows (Data Pipelines).
Synapse Data Engineering
The aim is to allow data engineers to quickly deliver value by providing out of the box tools, spend less time integrating multiple products and dealing with infrastructure setup and management.
The first step of this journey is to create a Lakehouse, a collection of files/folders/tables that represent a database over a data lake. Along with the lakehouse, two new default elements are created, a Warehouse and a Dataset.
The data within the Lakehouse is physically structured in two sections, Tables and Files. The first section represents the managed portion of the Lakehouse and stores tables of all file types (csv, parquet, delta, managed or unmanaged tables). The second section represents the unmanaged area of the Lakehouse and can store any file format.
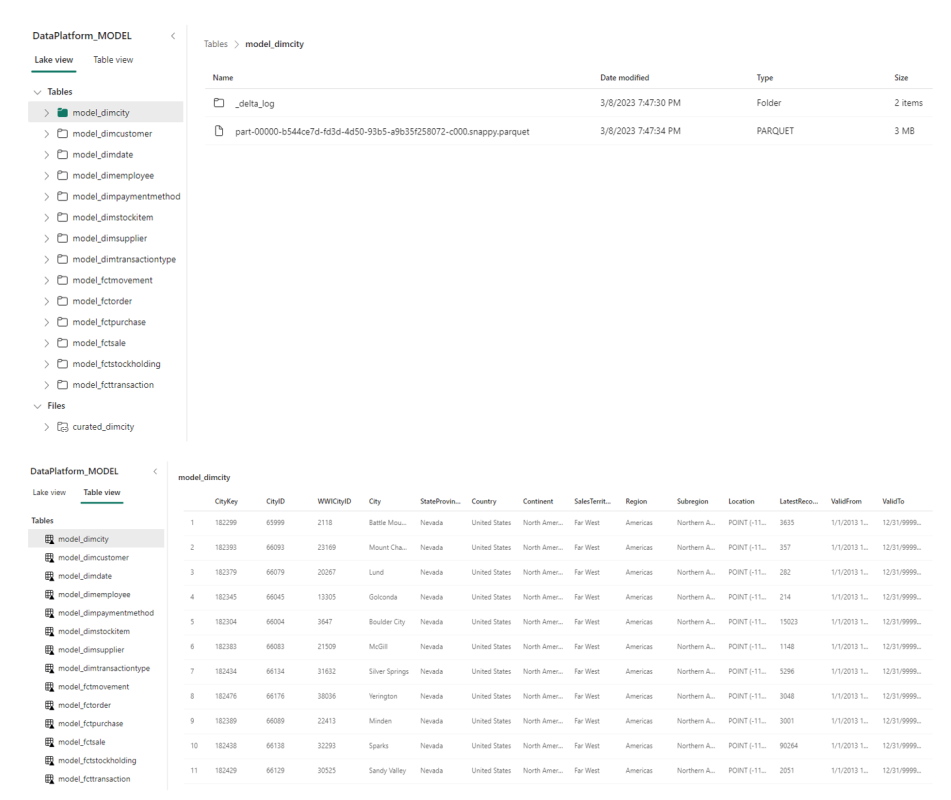
The default Warehouse element provides a similar experience to traditional SQL databases and contains a SQL endpoint that can be used to connect from other tools, such as Data Studio or SSMS. Data loaded to the lakehouse workspace as a delta table is automatically represented as a table in the Warehouse.
The default Dataset acts as the semantic model with metrics and is meant to be used by Power BI. Whenever a table and view is added to the lakehouse, the default dataset is updated.
To import data to the lakehouse, data engineers can use data pipelines or leverage the spark developer experience. Notebooks are available for data engineers to ingest, prepare and transform data and for data scientists to build machine learning solutions.
Synapse Data Warehouse
This experience is for teams that like to keep it simple and prefer to work with SQL and transactional data warehouses.

Fabric offers the first converged lakehouse and data warehouse experience. It enables teams to build a relational layer on top of the physical data in the lakehouse and expose it to analysis and reporting tools using T-SQL/TDS endpoints.
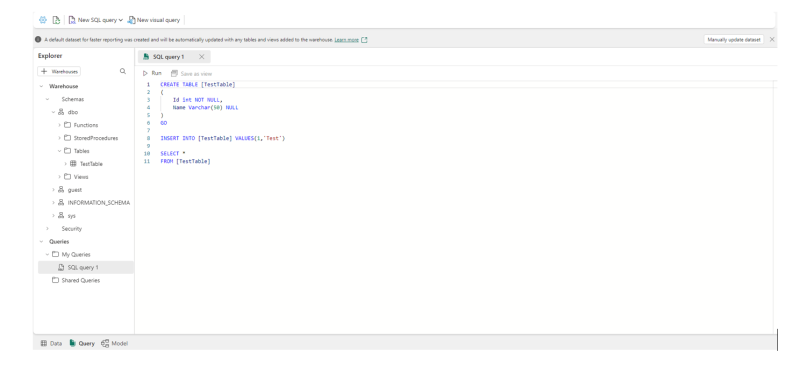
Data can be loaded into the Warehouse using the following options:
- COPY command
- From any database within the Fabric workspace using cross database queries
- Data pipelines
Organisations using Azure Synapse Dedicated SQL Pools will be able to upgrade to Synapse Data Warehouse in Microsoft Fabric and still take advantage of a robust, enterprise grade solution.
Synapse Real Time Analytics
This workload is for personas looking to work with fast pacing data, such as data streaming in from IoT devices and telemetry, and wanting to analyse big volumes of semi-structured data.
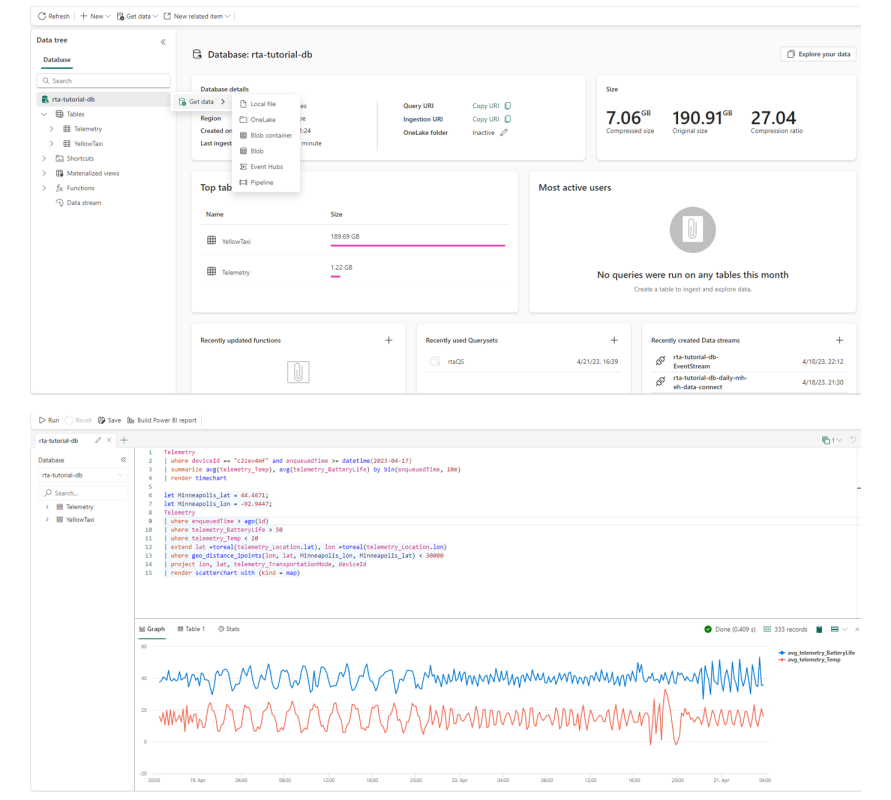
To analyse time series, telemetry or logs, teams can store the data in the KQL Databases and use Querysets to run queries using the Kusto Query Language (KQL). Kusto databases can store various data types and formats and leverage from automatic partitioning and indexing.
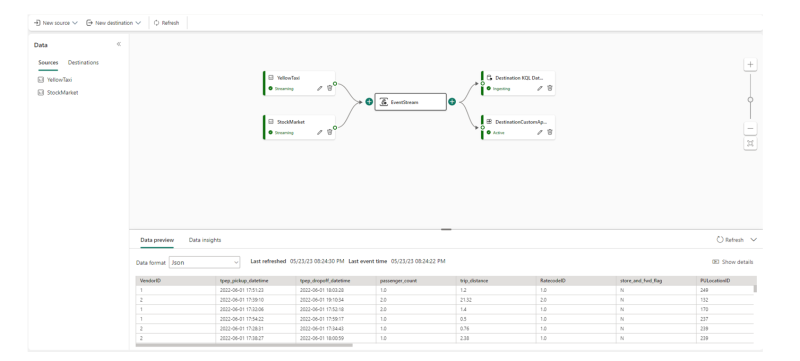
Eventstream
Eventstream a new low-code tool that can be used to capture, transform and route real-time events from Event Hubs and Custom Applications (eg. Kafka) to KQL databases, Lakehouses and Custom Applications.
Synapse Data Science
As expressed by the name, this experience is meant for data scientists to easily collaborate and build rich AI models and train, deploy and manage machine learning models.
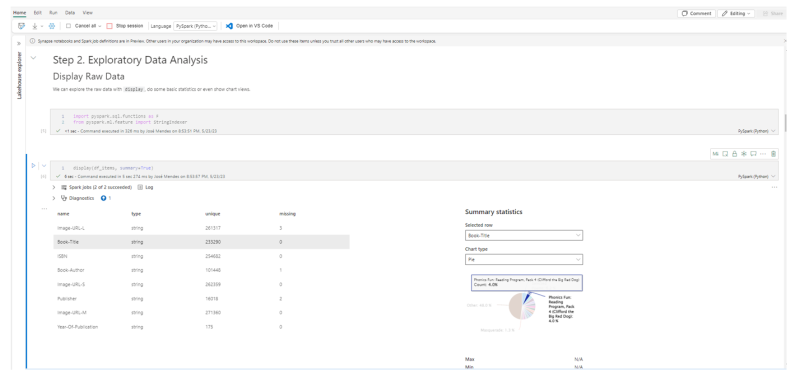
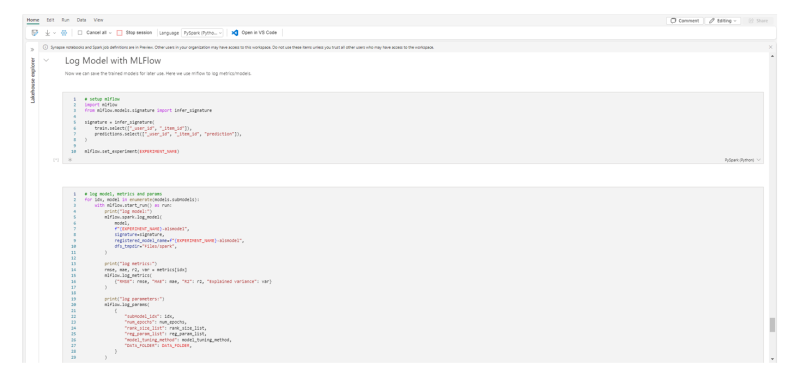
Data scientists can read the data from the lakehouse and use notebooks and VS Code to author experiences, use built-in ML tolls, such as ML Flow for model and experience tracking and the SynapseML Spark library to run predictions.
Data Activator
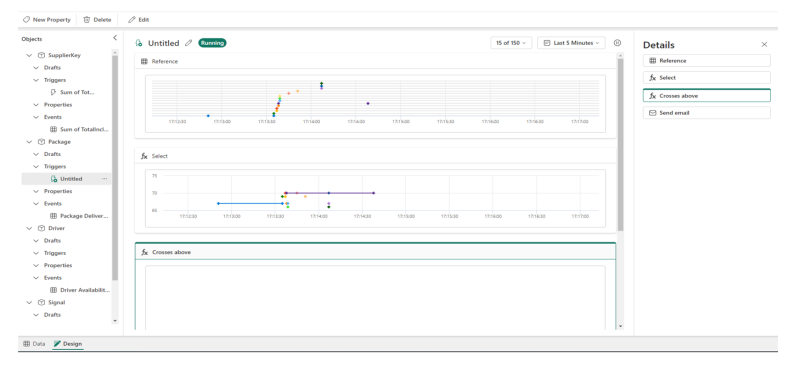
Yet to come to public preview, Data Activator is a new no-code tool to automatically take certain actions when a set of pre-defined patterns or conditions are detected in changing data. Users can use this tool to monitor data and trends in Power BI reports and Event Hub data streams and create actions, such as alerts or triggers to Power Automate workflows.
Power BI
With Fabric, two new and most expected features are introduced to Power BI, Direct Lake and Git Integration.
Direct Lake is a new engine capability suited to analyse very large datasets in Power BI that combines the performance of import mode with the ability to access the data in real time from Direct Query. This new technology allows Power BI to connect straight to the source without having to worry about data refreshes, since the data never leaves One Lake and doesn’t have to be duplicated into Power BI datasets.
Finally, we have the most expected native integration with Git. Using Power BI Desktop, users will have the capacity to save the reports in a new format and allow cross-collaboration, source control integration and use of CI/CD pipelines to push the reports across multiple environments.

I hope you are as excited as us to start planning a new journey with Microsoft Fabric. If you are interested to know more about the offering or how you can take advantage of all the new exciting features, please feel free to get in touch.