Microsoft Fabric is now Generally Available
What has happened?
On the 15th November Microsoft announced the general availability of Microsoft Fabric. Having seen Microsoft Fabric develop through our involvement in the private and public preview this is a really exciting announcement and all of us at Telefónica Tech are looking forward to seeing how it will fit into the solutions we are deploying to customers.
In this blog post we will cover the following:
- What is Microsoft Fabric? – a quick recap of what Microsoft Fabric is.
- Is it ready for production? – an overview of which features are included in the general availability announcement and which features are on the roadmap.
- I’m about to implement a new Data Platform, how does this change things? – where does Microsoft Fabric fit into greenfield Data Platform projects?
- I’ve got an existing Data Platform, how do I get started with Microsoft Fabric? – should you migrate existing workloads to Microsoft Fabric? If so, what are the migration paths?
- Where do I go next? – useful links and resources for getting started with Microsoft Fabric.
What is Microsoft Fabric?
In my previous blog post I gave a high-level view of what Microsoft Fabric is but let’s quickly recap.
Microsoft Fabric is the biggest development in the Data Platform space for a number of years and aims to bring the existing Azure Data Platform services under one software-as-a-service (SaaS) roof. The platform aims to enable the various personas involved in the development of a Data Platform solution to collaborate under one roof using a variety of different experiences and toolsets that are enabled by the platform, these include:
- Data Engineering
- Data Science
- Data Warehousing
- Real-Time Analytics
- Data Factory
- Data Activator
- Power BI
Microsoft Fabric builds on the existing Power BI platform we all know and love but adds a plethora of powerful toolsets on top that means Data Engineers, Data Scientists, Data Analysts and Business Users can all collaborate within a single, unified platform. This provides everybody with access to the same set of tools and means that we can truly democratise access to data across an organisation.
To make this possible, Microsoft Fabric sits on top of OneLake, which provides a unified and governed storage layer for data from across the organisation. This enables you to access data from business systems, existing Azure Data Lake Storage Gen2 accounts, applications such as Dynamics 365 and data from other cloud providers such as Amazon S3 using a single interface. All data is stored in the open source Delta format, enabling all of the compute tools within Microsoft Fabric to read and write data stored within OneLake, which provides true compute/storage separation.
The diagram below illustrates the various experiences available within Microsoft Fabric:
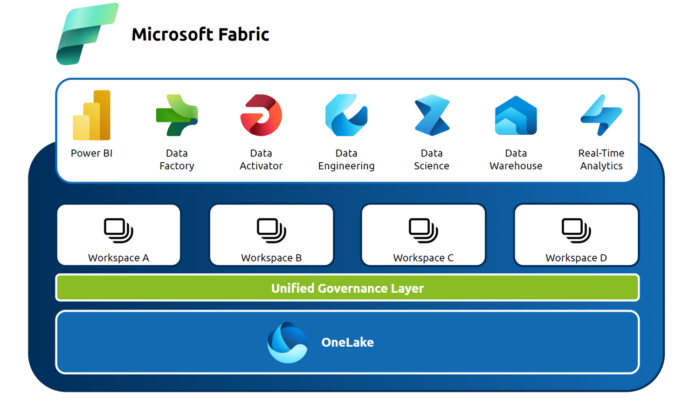
There are lots of really exciting features that the new architecture enables such as v-order and Direct Lake connectivity however, in this blog post we’ll keep it high-level.
My colleague José Mendes, Head of Data Engineering at Telefónica Tech, provided a great overview of the Microsoft Fabric public preview features that have now carried through to general availability in his blog post. The rest of the Telefónica Tech team have also been blogging about our experience of the various features, these posts can be found here.
Is it ready for production?
Microsoft Fabric has now reached general availability, but does this mean that it’s ready for production use?
In short, general availability provides production SLAs and support from Microsoft but there are still a number of features to be developed, which are outlined in the Microsoft Fabric roadmap. The product team is moving at a rapid pace and will be deploying features on the same monthly release cycle that is adopted by Power BI, so features will be coming to the product quickly.
Some key items on the roadmap that I see as being key before some customers can adopt Microsoft Fabric are outlined below:
- Private Endpoint Support – Q2 2024
- Fine-Grained Security in OneLake (public preview) – Q2 2024
- Lakehouse Schema Support – Q2 2024
- Data Factory Git Integration – Q1 2024
- Data Factory Connection Parameterisation – Q1 2024
In summary, now Microsoft Fabric has reached general availability it is ready for production use however, the product is still being actively developed and there are a number of key features that need to be in place before it will be ready for some customers to adopt.
I’m about to implement a new Data Platform, how does this change things?
If you are about to embark on a Data Platform implementation, then the Microsoft Fabric announcement may make you reconsider your options. Below is my view on what you should do next:
- If any of the features that are currently not in the generally available version of Microsoft Fabric are not a showstopper for you then adopt Microsoft Fabric for your end-to-end Data Platform implementation.
- If there are features that are not available in the general availability release that are a showstopper then you should still build on top of the lakehouse architecture using the Delta Lake format but continue to utilise existing toolsets such as Azure Synapse Analytics or Azure Databricks. This will ensure that a migration to Microsoft Fabric is simple when the time comes.
If you need to use an existing tool such as Azure Synapse Analytics then it is still possible to utilise OneLake for data storage, as outlined here.
Where Microsoft Fabric is the right choice for you now, we have defined a reference architecture for data warehousing workloads that is based on the medallion architecture and utilises various Microsoft Fabric experiences to pull together an end-to-end data processing pipeline that can be used to rapidly deliver curated data for analysis in Power BI and other tools. The diagram below illustrates this architecture:
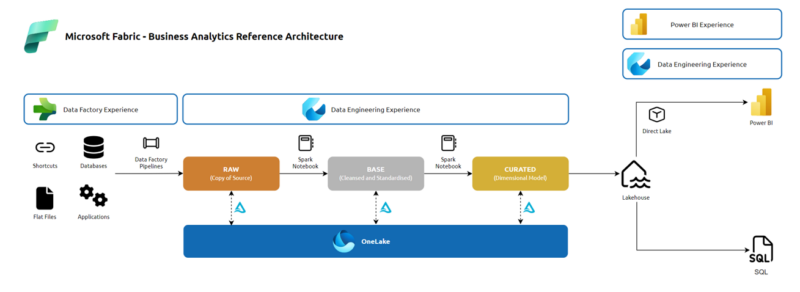
The architecture above is focused on data warehousing workloads however, this can be expanded to cater for data science and real-time analytics workloads by using other components in the Microsoft Fabric stack.
I’ve got an existing Data Platform, how do I get started with Microsoft Fabric?
Firstly, if you have an existing Data Platform there is no need to do anything right away. Microsoft will continue to support PaaS services such as Azure Synapse and there are no plans to decommission any existing services however, it is worth considering the potential value that Microsoft Fabric can bring to your organisation by taking advantage of the new features.
If you have existing data workloads and would like to consider migrating them to Microsoft Fabric the first step is to assess your workloads and begin to build a picture of their suitability for migration to Microsoft Fabric. We need to consider some of the following items:
- Type of Workload – Data Engineering or Data Science
- Current Implementation – On-Prem, Appliance, Synapse
- Criticality
- Number of Users
- Volume of Data Being Processed
- Data Latency Required
- Type of Data Being Processed – Structured vs Unstructured
- Source System Types
Once we have this data, we can then start to understand whether the workload is suitable for migration to Microsoft Fabric based on the features available and decide on a target architecture for the workload.
In the diagram below we have identified common target architectures for various types of workloads:
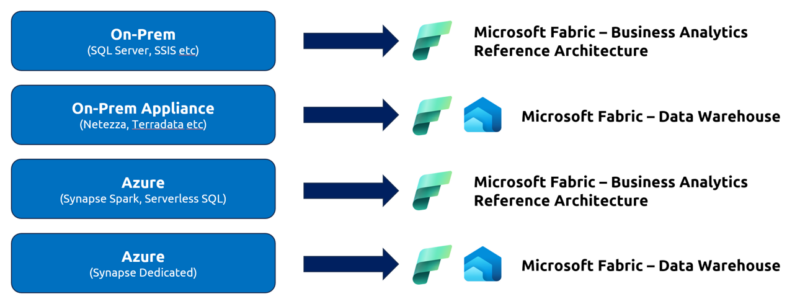
Once we have decided to migrate a workload and identified the target architecture, we can begin to perform the migration; in some cases, this may be a lift and shift but in other cases we may need to re-engineer the workload as we move it into Microsoft Fabric.
Where do I go next?
If you’d like to find out more about Microsoft Fabric and discuss how it fits into your data strategy, get in touch today.