In 2023, about 5 billion people used the internet. With so many people contributing and consuming content on the internet, vast quantities of data are available. Web scraping is a technique that allows us to tap into this data, so that we can derive interesting insights on a variety of topics.
In this article, we will build a tool that can be used to analyse the titles of YouTube videos. Specifically, we will aim to answer the following question:
Which words contained within video titles lead to the most clicks?
The tool will be built using the following Python modules:
- Selenium: to scrape a dynamic web page.
- NLTK: to perform natural language processing (NLP) analysis to extract key words.
Please note the following:
- The full model code as well as the extracted data can be found here.
- To view some of the images in this article properly, you may have to zoom in.
The Web Scraping Bit
Web scraping is the process of data extraction from websites. There are many available Python modules that can be used to carry out and automate this process. In this article, we use Selenium, as it contains the functionality to cope with dynamic websites (websites that can change their content based on user input, database interactions, or other external factors).
At a basic level, the web scraping process in Selenium is as follows:
- Configure the web driver – allowing you to create a browser instance.
- Extract data from the desired web page by finding the appropriate element(s).
- Interact with the web page (e.g., scrolling) to load more data (only required in some instances).
Configure the web driver
In this article, we will use Chrome. The Chrome web driver can be downloaded here. After downloading the driver, we can then configure the driver in Selenium as shown below:
 Running this code results in a Chrome instance being created in which we can load web pages to extract data from.
Running this code results in a Chrome instance being created in which we can load web pages to extract data from.
Extracting the Data
The data we will be extracting relates to YouTube videos from some science and education channels that I enjoy watching – a list of these can be found at the end of the blog (e.g., Veritasium). For each video, the data we will extract is as follows:
- Title
- Number of views
We will also extract the following information for each channel:
- Name
- Number of subscribers
We will be extracting data from the Videos page. To extract data, we can pass Selenium some source code to search the page for. From the image below, we can see all of the required information relating to a video is contained within the class called style-scope ytd-rich-grid-media. Note, this view is accessible using the Inspect button available upon right-clicking on the web page.
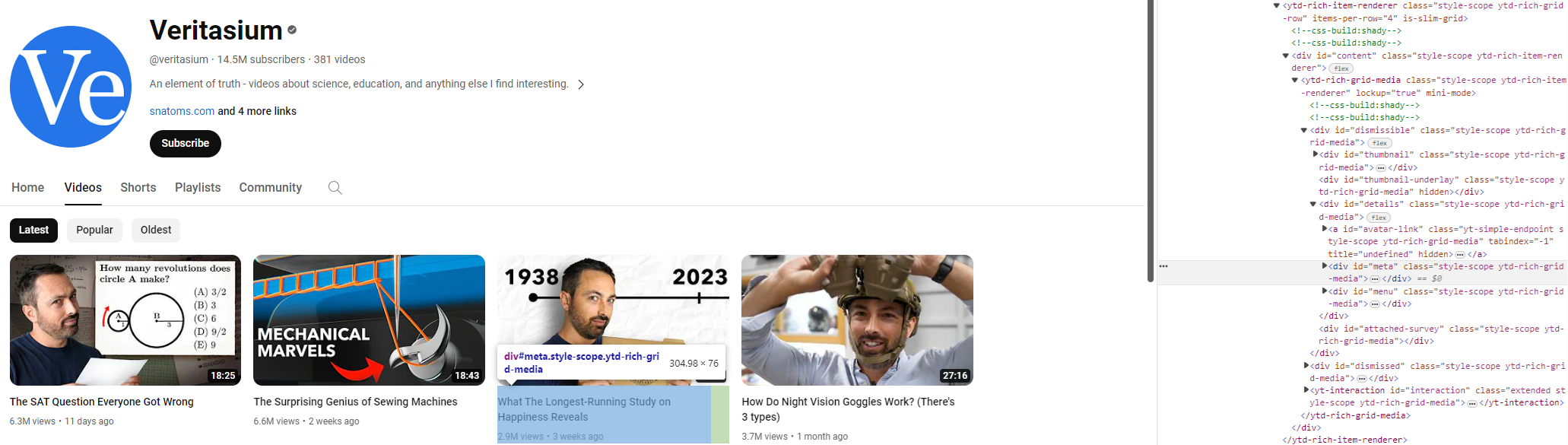
This class will be present for all YouTube videos on the page. The find_elements() function will automatically find all elements which match a specific pattern. To find all elements of the class, style-scope ytd-rich-grid-media, we can do the following:
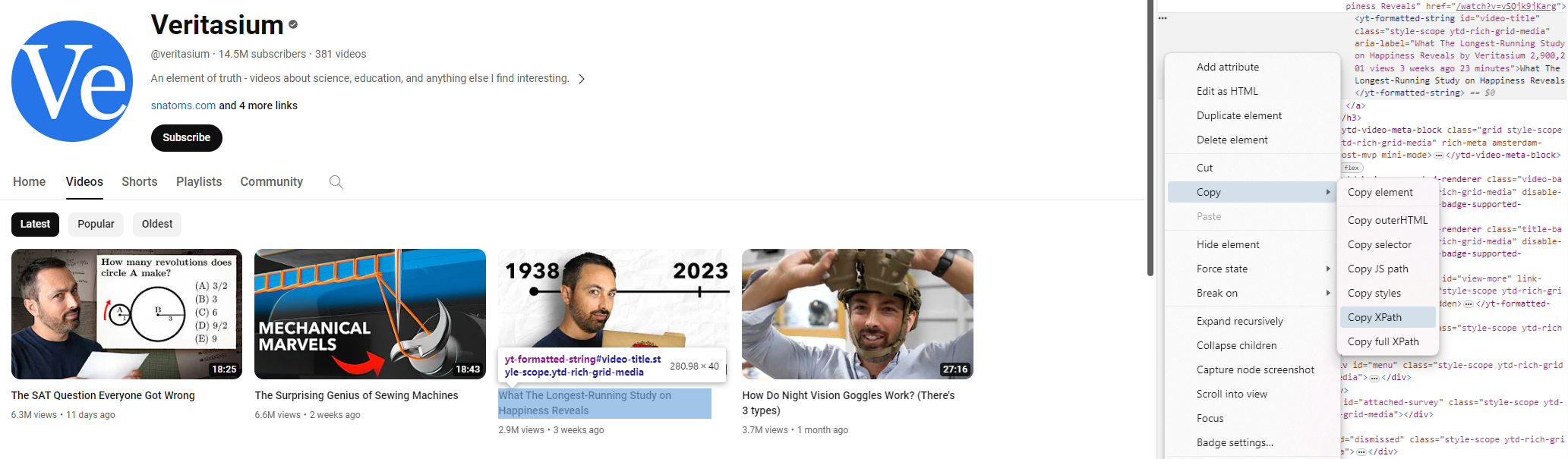
 After accessing this information, we can then locate the title specifically through passing the XPath – as shown below:
After accessing this information, we can then locate the title specifically through passing the XPath – as shown below:
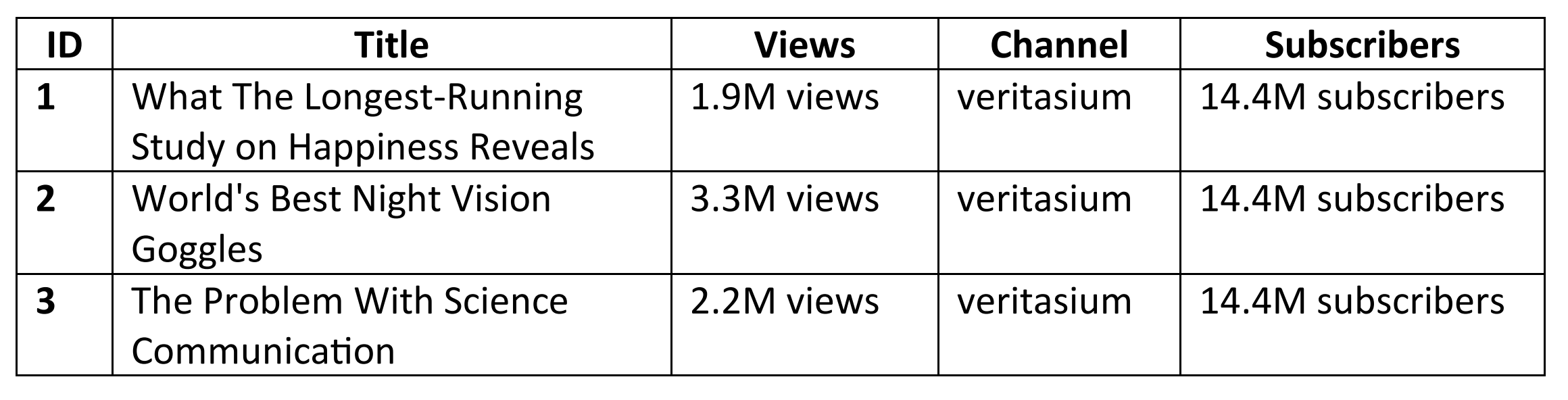
 We can perform the same procedure to extract the other relevant data. An excerpt of the raw data output is shown below:
We can perform the same procedure to extract the other relevant data. An excerpt of the raw data output is shown below:
 Scrolling Down
Scrolling Down
 Scrolling Down
Scrolling DownWeb scraping applications don’t just allow us to extract data, they also allow us to automate interactions with the web page. For example, to access all YouTube videos from a particular channel, it is necessary to scroll down until all videos have loaded. This can be automated using the following code:
 The Natural Language Processing Bit
The Natural Language Processing Bit
 The Natural Language Processing Bit
The Natural Language Processing BitBefore doing any analysis on the data, the following data cleansing steps must be applied:
- Converting the data type of the Views and Subscribers columns to integer.
- Normalising the number of views for each video based on the number of subscribers associated with each channel. For this, the following equation is used:
(Number of Views / Number of Subscribers) X 106
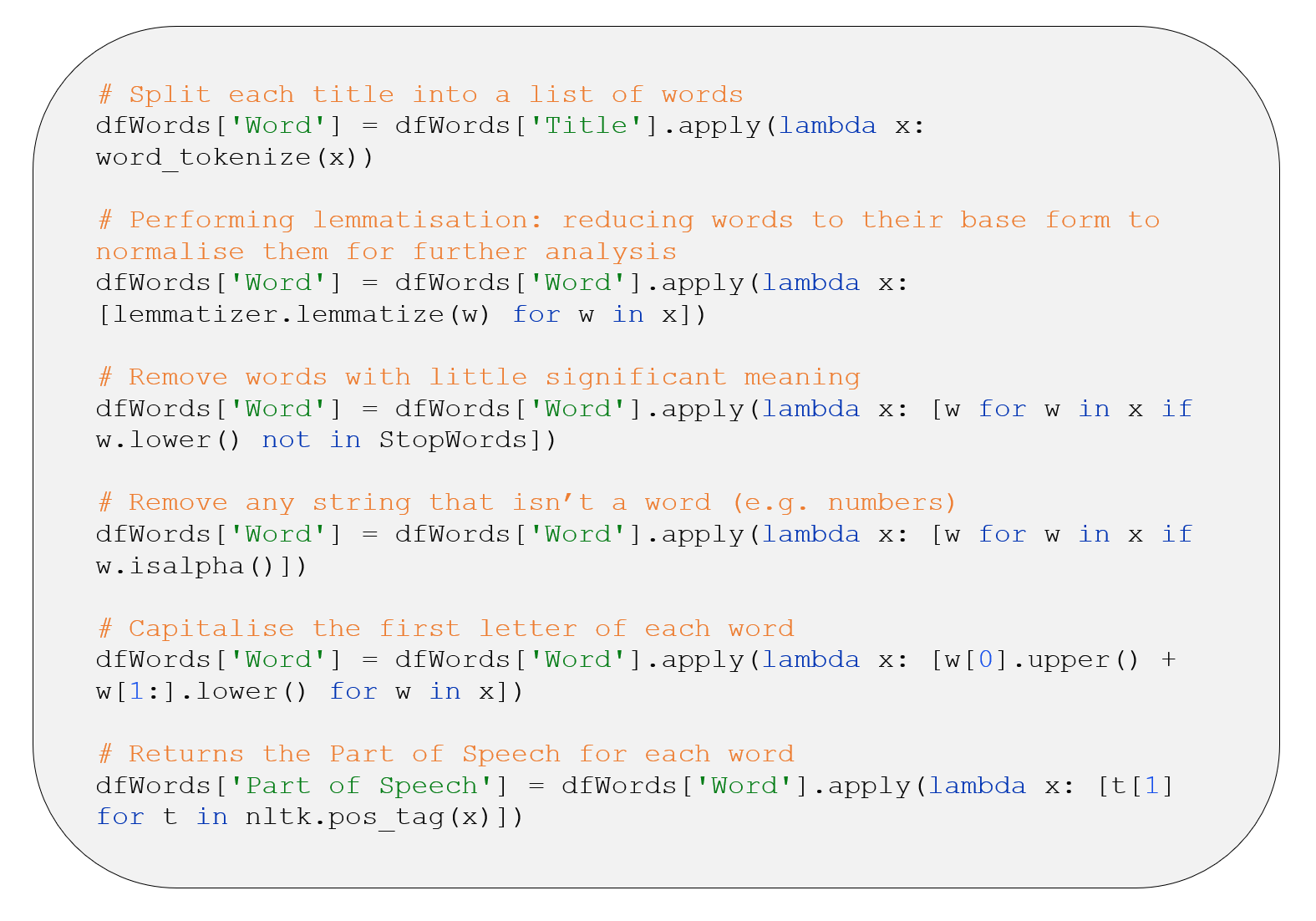
Now we can use the Python module, NLTK, to do some basic NLP analysis – the principal code for which is shown below:
 After the analysis, we explode, aggregate and filter the output. This includes the following:
After the analysis, we explode, aggregate and filter the output. This includes the following:
- Computing the number of videos featuring each word.
- Computing the average and median number of views of these videos for each word.
- Only including nouns and adjectives in the output as these tend to hold the greatest meaning.
This results in a dataset, an excerpt of which is shown below:
 The Findings Bit
The Findings Bit
 The Findings Bit
The Findings BitFrom the analysis, we can derive some interesting findings. The figure below shows a word cloud featuring the words present in the titles of the YouTube videos included in the study. There are two features of this word cloud:
- Size: The larger the word, the larger the Median Views Normalised.
- Colour: The colour of the words refers to the number of YouTube videos whose titles feature that word – please refer to the scale shown in the figure.

From the figure below, it can be seen that:
- Words such as Immune, Zero, Bomb, Destroy, Hole etc. tend to result in the largest number of views. To give some context, shown below are some YouTube videos associated with these words (ordered by Views Normalised):
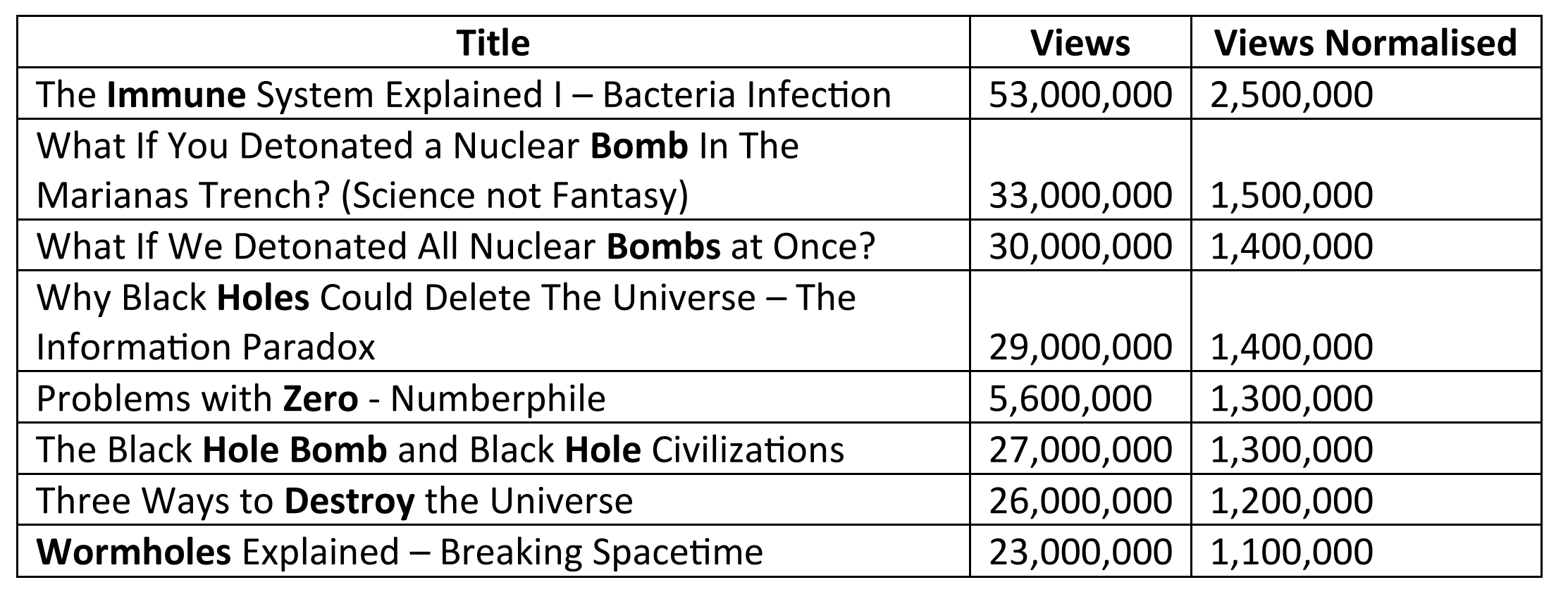
- Words such as Work, Solve and Universe, etc. tend to result in a large number of videos. To give some context, shown below are some YouTube videos associated with these words (ordered by Views Normalised):
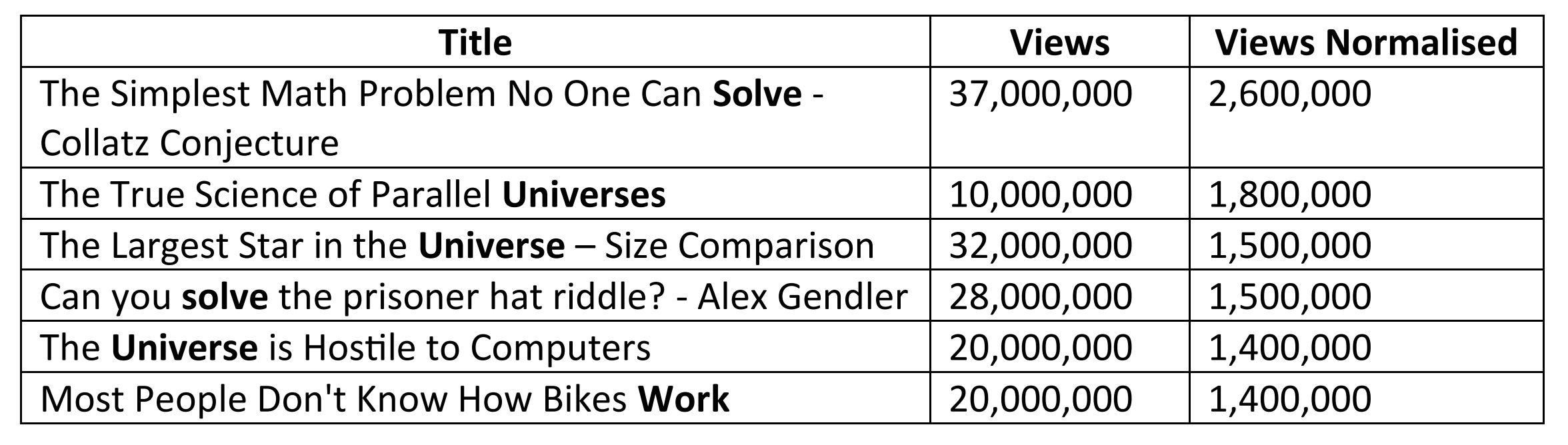 Note, these findings are only valid for the sample of data that has been used in this study and are subject to various model assumptions that we have made.
Note, these findings are only valid for the sample of data that has been used in this study and are subject to various model assumptions that we have made.
The Wrap-up Bit
In this blog, we have presented a run-through detailing the fundamental steps required to:
- Extract data from a website using Selenium and;
- Analysing text data using NLTK to derive some interesting insights.
Hopefully with this new knowledge, you can now go and build your own web scraping and analysis models!