During FabConEurope, Microsoft announced the public preview of Azure Databricks Mirrored Catalog, a new feature that will allow users to access Databricks Unity Catalog (UC) tables directly from Fabric. This approach differs from the previous Microsoft recommendation (described by my colleague Matthew Greenbank here), where a user would need to run a notebook to extract UC metadata and create shortcuts using the Fabric API. Instead, when the Fabric item is created using the UI, users will have access to a read-only, continuously replicated copy of the Databricks UC in OneLake and will have the possibility to explore the data using the SQL Endpoint or directly create Power BI reports using Direct Lake mode.
In this blog I’ll demonstrate how to create the mirrored database and explore some of the pros and cons of this new approach.
Pre-Requisites
Before you embark in this new exciting journey, you should be aware of the following pre-requisites and constraints:
- As stated in the feature name, you require an Azure Databricks workspace with UC enabled
- The Databricks workspace can’t be behind a private endpoint. Similarly, the storage account that stores the UC data can’t be behind a firewall. If you use workspace IP ACLs, you will need to add the Power BI and Power Query Online service tags
- Only UC managed and unmanaged tables are supported. The following objects can’t be mirrored:
- Tables with RLS\CLM policies
- Lakehouse federated tables
- Delta sharing tables
- Views and Materialised views
- Streaming tables
- External tables that don’t support Delta format
- Other non-table object type
- Mirrored tables can’t be renamed
- UC policies and permissions are not replicated in Fabric. The security model must be replicated in Fabric
- The credential used to create the connection to UC in Fabric will be used for all data queries. The recommended approach to authenticate to the Databricks workspace is to use a Service Principal over an Organisational Account. Additionally, you must be a user or an admin of the databricks workspace
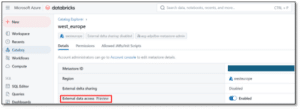
- You should enable the External data access flag on the Databricks metastore

- The organisational account or service principal used in the Fabric connection must have External Use Schema privilege on the UC schema that contains the tables that will be mirrored. If this is not applied, the tables will be visible in the Fabric database but the content won’t be available.

- Grant Use permission on the relevant catalogs and schemas. Grant Select and Modify on tables
How it works
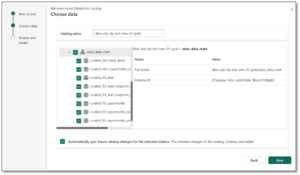
Each Mirrored Azure Databricks Catalog item in Fabric maps to a single catalog with UC. When the connection is established, the catalog structure is replicated and synchronised every 15 minutes or on demand. UC authorises the data access and Fabric/OneLake reads directly from the storage account storing the UC data.
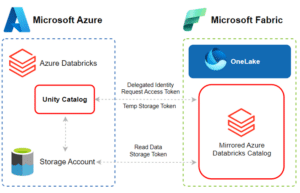
The data is never copied, however it is always in sync because in the background a shortcut for each UC table is created, ensuring that any changes applied in Databricks are replicated in Fabric. The data becomes immediately available with no added latency to copy or move the data. It is possible to mirror the entire catalog or a combination of schemas and tables, although, you will only be able to select the objects that you have access to as per the privileges defined in the UC. By default, the Automatically sync future catalog changes for the selected schema is enabled, however, it is possible to disable this setting and set static mapping to only mirror a subset of objects.
Setup
- Start by enabling the preview in the Fabric Admin portal. This can be set at the tenant/capacity level and enabled to all/specific users

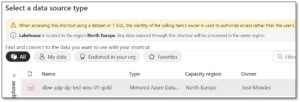
- Once enabled, you will be able to see the new item in the Data Warehouse Experience.

- Select an existing or create a new connection

- Select the catalog, schema and tables . Provide a unique name and create the new artifact

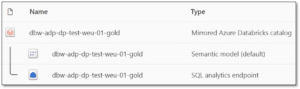
- Once created, three new items are added to the workspace:
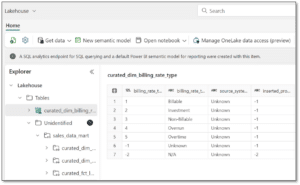
- Mirrored Azure Databricks catalog item – allows you to explore the replicated tables and monitor/manage the catalog
- Default Semantic Model – allows you to explore the data in Power BI using Direct Lake mode
- SQL analytics endpoint – allows you to explore the data using T-SQL commands

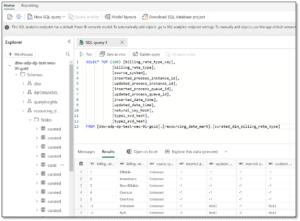
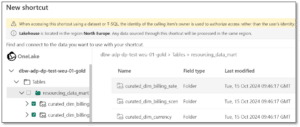
- To explore the data using a spark notebook, you need to create a shortcut in the lakehouse. At the time of writing this blog, it is not possible to select the entire catalog. When performing this action, a folder named Unidentified is added and the shortcut is not recognised as a delta table. Instead, individual tables must be selected.
Final Considerations
Databricks UC mirrored databases allow Fabric users to explore the data stored in Databricks UC tables and further transform or visualise it using the tools they are most comfortable with, however, is this the best solution? The answer is “it depends on the use case”.
If you have a Databricks based data platform, what is the drive to replicate the data to Fabric? Are you looking to enable citizen developers to use low-code no code tools to explore the data, to leverage Direct Lake to build your reports, to integrate the data with other Microsoft products that better integrate with Fabric, such as Microsoft Teams or even use AI and ML tools such as Copilot Studio or build Fabric AI Skills? Additional considerations are:
- Cost: If you do not have a Fabric capacity, then you will need to acquire at least one (the recommendation is to have two, one for non-prod and another for the production environment)
- Complexity: You are potentially expanding your architecture by adding a new SaaS tool that requires a new set of considerations, from security to governance.
- Effort: If you are using one of the non-supported objects, such as views, you may have to replicate the logic in Fabric. This will require additional effort and will no longer keep the data in a centralised location
- Networking: At the time of writing, private endpoints and firewalls are not supported. If you plan to further secure the data platform in the future, than this might hinder the plans since this item would no longer be supported
If none of the limitations or above considerations apply, then, this feature might be just what you need to take your analytical solution to the next level. If you would like to understand how Telefónica Tech can help accelerate your data potential, please get in touch here